 +33 4 78 17 21 16
+33 4 78 17 21 16-


- Accueil
- |
-
 L'information à 360°
L'information à 360°
- |
- Solutions
- |
- Services
- |
- Clients
- |
- Société
- |
- Actualités
6 La navigation dans le manuel de Kentika est réservée aux utilisateurs identifiés
Thesaurus : import
Appartenance & droits
Thesaurus : import
Le thesaurus est un outil professionnel qui offre une grande richesse et pertinence au niveau de l'indexation et de la recherche. Un thesaurus est composé d'un ensemble de descripteurs qui se déterminent les uns par rapport aux autres. Les relations qui existent entre les descripteurs sont donc primordiales. L'import d'un thesaurus est en cela différent des autres imports de données : les relations sont traitées avec beaucoup de précision.
Il est possible d'avoir la même expression utilisée dans deux branches différentes (exemple : "grue" comme engin de chantier et "grue" comme oiseau). Seul son rattachement hiérarchique (terme générique) permet de savoir de quel type de grue il s'agit. Un simple import de texte pourrait donc introduire des erreurs dans le thesaurus.
Lorsqu'un descripteur est affecté à un enregistrement, c'est son Record_Num qui permet de faire le lien. Aussi, si on le supprime et qu'on l'importe à nouveau, le descripteur ré-importé n'aura plus le même Record_Num (sauf dans le cas de thesauri packagés) et le lien avec les enregistrements ne sera pas regénéré. Il ne faut donc pas utiliser les fonctions d'export / ré-import du thesaurus en texte tabulé comme une option permettant de structurer simplement son thesaurus (sauf en phase d'initialisation de la base ou lors de l'ajout d'une branche complète indépendante du reste du thesaurus).
NB : l'outil d'importation de données textuelles est utilisable également pour importer un thesaurus. Cependant, il demande une bonne maîtrise pour analyser et reproduire correctement les relations.
Installation
Cette fonction est appelée via un script pré-programmé affecté soit au menu "exploitation", soit au bouton "thesaurus / process" dont le contenu est :
New Process
IMP_THES
Veillez à affecter une autorisation élevée à cette fonction sinon, un utilisateur non averti pourrait désorganiser le thesaurus en place.
Formats possibles
Cette fonction accepte deux formats en entrée : format interne Kentika (tel qu'indiqué ci-après) et texte tabulé.
Format interne
Un fichier comportant un thesaurus ou une branche de thesaurus doit être généré à partir du dialogue "Thesaurus : édition de listes".
Texte tabulé
Ceci est un moyen rapide de constituer un thesaurus. Cependant, vous devez vous assurer que ce fichier est bien formé, à savoir : un descripteur par ligne et une tabulation par niveau.
Exemple de fichier bien formé
- histoire
- Antiquité
- Antiquité chinoise
- Antiquité égyptienne
- Antiquité grecque
- colonisation grecque
- époque classique
- guerres médiques
- époque hellénistique
- époque mycénienne
- guerre de Troie
- Antiquité romaine
- Bas-Empire : 284-395
- invasion barbare
- colonisation romaine
- Empire romain
- République romaine
- guerre des Gaules
- guerres puniques
- Bas-Empire : 284-395
- Antiquité
Notion de "thesaurus autonome"
Un thesaurus autonome est un tout qu'il convient de conserver tel quel. C'est le cas des thesauri fournis par certaines institutions. Un tel thesaurus peut être importé et mis à jour en toute sécurité et en conservant l'intégrité des données.
Générer un fichier d'export d'un thesaurus autonome
Un tel thesaurus a un nom et un numéro qui doit être fourni par l'équipe Kentika si vous voulez éviter des confusions entre différents thesauri officiels.
Lors de l'enregistrement du fichier sur le disque, il suffit de maintenir la touche majuscule enfoncée.
Dialogue d'import
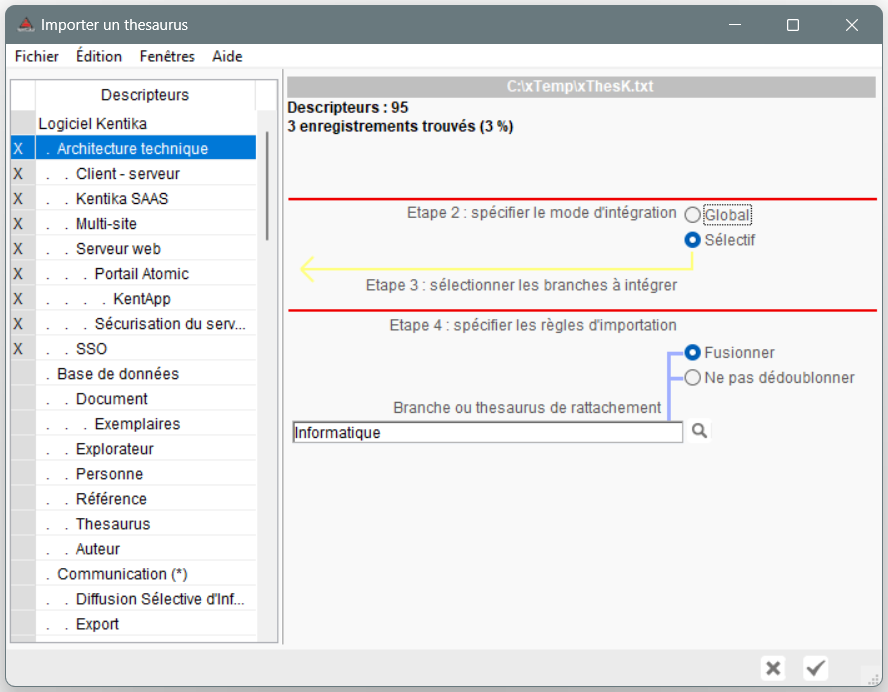
Présentation du thesaurus à importer à gauche.
Etape 1 : vérification
Analyse complète du thesaurus à importer par rapport à celui présent dans votre base de données : les descripteurs déjà présents sont présentés avec un (*).
Etape 2 : mode d'intégration
Mode "global" : pour importer l'intégralité du thesaurus
Mode sélectif : pour n'importer qu'une partie du thesaurus, sélectionner les branches à intégrer
Etape 3 : sélection des branches
Dans le cas d'un import sélectif, permet de choisir les branches à importer
Un clic dans la colonne à gauche d'un descripteur sélectionne le descripteur ainsi que toute sa descendance si ce dernier n'est pas sélectionné / désélectionne le descripteur et sa descendance si ce dernier est sélectionné. Il est ensuite possible de désélectionner un descripteur situé à un niveau inférieur. Un clic en regard du descripteur en maintenant la touche "majuscule enfoncée" sélectionne / désélectionne le terme seul (ie : sans sa descendance).
Etape 4 : règles d'importation
Les options proposées dépendent du mode d'intégration et permettent de régler la manière dont doit être traité le thesaurus importé.
Nouveau thesaurus
Le thesaurus est importé sans tenir compte du thesaurus en place. Aucun dédoublonnage ni fusion avec l'existant. Dans le cas d'un thesaurus autonome, les Record_Num des descripteurs importés porteront des numéros calculés de la manière suivante : Record_Num de l'enregistrement importé + (100 000* numéro du thesaurus)+10 000 000.
NB : ce principe de renumérotation permet ensuite à l'application de retrouver simplement les descripteurs appartenant à un thesaurus donné identifié par son numéro.
Fusionner
Si un descripteur importé figure déjà dans le thesaurus, il sera ignoré lors de l'import et ses descripteurs spécifiques seront rattachés au descripteur trouvé.
NB : la recherche de descripteurs présents porte sur l'intitulé du descripteur sans tenir compte des lettres accentuées ou des majuscules / minuscules. Ainsi si on tente d'importer le descripteur "Elève" et qu'il existe un descripteur "ELEVE" dans la base de données, le descripteur "Elève" sera ignoré.
Ne pas dédoublonner
Aucun contrôle d'existence n'est effectué.
Mise à jour
Cette option permet de considérer le thesaurus comme un tout et de l'assimiler à une branche (ou à un thesaurus) existant dans la base de données. Si des descripteurs ont été ajoutés dans le thesaurus importé, ils seront ajoutés à votre thesaurus. Par contre, s'ils ont disparu, le choix du traitement est proposé.
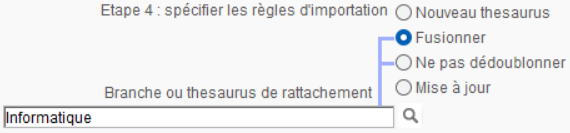
Option complémentaire relative aux descripteurs qui ne figureraient plus dans le thesaurus importé
Cette option est à privilégier dans le cas de la mise à jour d'un thesaurus autonome.
Branche de rattachement
Dans le cas d'un import de thesaurus avec une des options autre que "Nouveau thesaurus", si un descripteur n'a pas de terme générique, il devra être rattaché à une branche par défaut. Vous devez indiquer quelle sera cette branche. Sinon, ces descripteurs sans terme générique seront considérés comme des descripteurs maîtres.
Validation
Les mises à jour sont effectuées globalement si vous cliquez sur le bouton de validation et que vous confirmez les messages qui vous sont proposés.
Contrôlez immédiatement le résultat et, en cas d'un résultat obtenu ne correspondant pas au résultat souhaité, recharger une sauvegarde.
Concevoir un thesaurus avec excel
Préparation du fichier xlsx
La feuille de calcul doit comporter un descripteur par ligne, avec un décalage pour matérialiser le niveau.
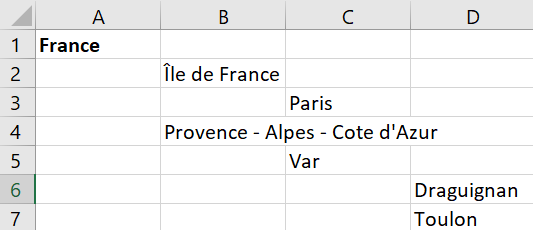
Contrôler les niveaux, avant de procéder à l'étape suivante
Préparation du fichier csv à importer
Demander à "Exporter" et choisir comme format : texte avec séparateur : tabulation
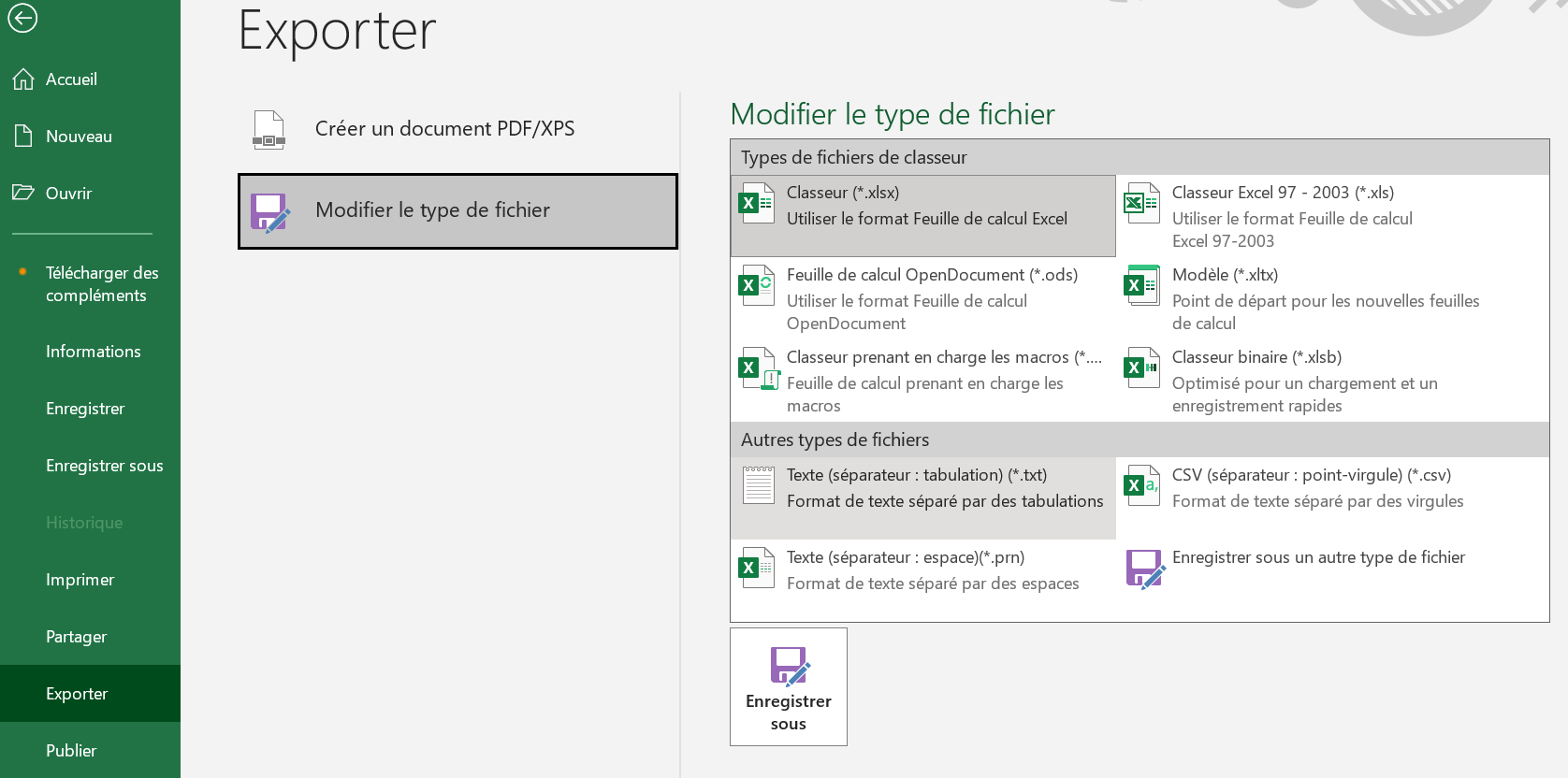
Importer le fichier dans kentika
A l'aide de l'option décrite ci-dessus, sélectionner les options voulues.
Pour ajouter un synonyme (employé pour), le séparer du descripteur par | , exemple : "Provence - Alpes - Cote d'Azur|PACA"
Pour forcer un mode de décodage (ex : 12 pour ISO-8859-9, valeur par défaut), maintenir la touche "Ctrl" enfoncée après avoir sélectionné le fichier à importer et le renseigner dans le dialogue.
Powered by KENTIKA Atomic - © Kentika 2025 tous droits réservés - Mentions légales