 +33 4 78 17 21 16
+33 4 78 17 21 16-


- Accueil
- |
-
 L'information à 360°
L'information à 360°
- |
- Solutions
- |
- Services
- |
- Clients
- |
- Société
- |
- Actualités
6 La navigation dans le manuel de Kentika est réservée aux utilisateurs identifiés
Filtrer les accès au serveur web
Appartenance & droits
Filtrer les accès au serveur Web
Introduction
Mettre en place une stratégie de filtrage répond à deux types de préoccupations :
sécurité : limiter l'accès (une condition doit être remplie pour accéder au site), refuser l'accès ;
performance : éviter que votre site soit accédé en permanence par les robots d'indexation, ce qui peut avoir un effet négatif sur les performances.
Pour savoir si votre site est sollicité de manière excessive par des robots, observer le contenu du log.
Rappel : le serveur web produit, chaque jour, un fichier log qui se trouve dans le répertoire WEBLOG du dossier temporaire AKTemp.
Premier indice : si vos fichiers de log ont une taille moyenne supérieure à 1Mo, il est probable que des robots effectuent une aspiration.
Attention, il y a trois sortes de robots :
- Les robots d'indexation (Google, Bing, etc.)
- Les robots "aspirateurs" qui indexent un maximum de données pour des raisons malhonnêtes (espionnage industriel, constitution de listes d'adresse emails...)
- Les robots pirates qui recherchent des failles de sécurité
Les premiers sont parfois nécessaires, les autres non. Une autre page explique comment optimiser Kentika pour autoriser les robots d'indexation.
Analyser le contenu d'un fichier
Les robots ont la particularité de :
travailler de jour comme de nuit (cf : heure de l'URL)
demander le fichier robots.txt
explorer systématiquement tous les liens, y compris les "PrintRecord.htm"
utiliser un plage d'adresses IP toujours la même mais des adresses IP différentes.
Paramétrage
Accessible depuis l'écran de paramétrage du serveur web, l'écran de filtrage permet de définir trois types de règles :
# : refuse, si la condition est remplie, l'utilisateur est systématiquement renvoyé vers la ressource dont le nom est :"File://accessdenied.htm" (dans l'exemple ci-dessous, l'utilisateur dont l'adresse IP est 192.168.0.53 se voit interdire l'accès au site).
* : accept, l'adresse IP est acceptée, même si une requête "robots.txt" émande de cette adresse.
R : robots, si la condition est remplie, la ressource "File://robots.htm" est systématiquement renvoyée (quelque soit la page demandée).
T : tempo, le contenu de la page est transmis mais l'URL est temporisée (10 secondes) afin d'éviter une fréquence de recherche trop élevée et les pages calculées ont une date d'expiration à 10 jours (alors que pour un internaute normal, elle expire immédiatement afin d'éviter qu'elle soit conservée dans son cache).
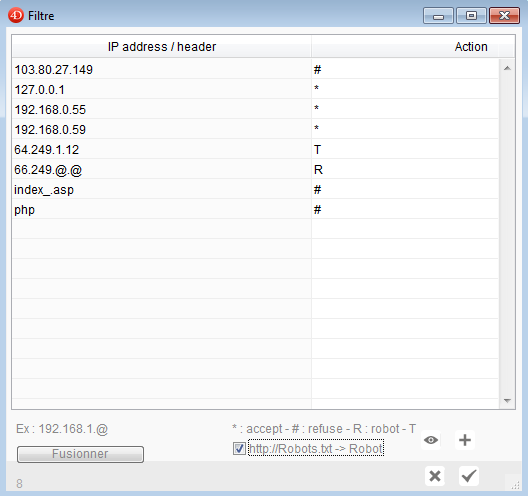
IP addresse ou header : la condition exprimée ici doit être soit une adresse IP (doit contenir 4 éléments séparés par des . ), soit une expression du header http (si l'expression n'est pas composée de 4 éléments séparés par des . l'expression est cherchée dans le header).
Kentika ne propose, par défaut, aucune page contenant ".php" dans son nom. De nombreuses recherches de failles de sécurité par des pirates passe par une tentative de prise de contrôle via des pages php. En filtrant .php, l'adresse IP d'origine sera refusée. Attention : si votre base comporte des contenus relatifs au php, il est possible qu'une recherche faite par un internaute provoque un rejet de ses requêtes.
Pour modifier une valeur : faire un double-clic sur la valeur à modifier.
Validation : le bouton vert valide la saisie, l'enregistrement dans la base (et donc sa prise en compte dans le fichier de données) n'est effective que lors de la validation de l'écran de paramétrage (Appliquer).
Détection des robots
En cochant la case : "http://Robots.txt -> Robot ", dès qu'une requête concernant le fichier "robots.txt" sera reçue par le serveur Kentika, l'adresse IP dont elle émane sera automatiquement ajoutée à la liste avec le code action "R" ou "T" si vous avez utilisé au moins une fois ce code dans la liste des filtres en place.
A propos des robots
Il est déconseillé de demander à un robot de ne plus être indexé car cette décision est définitive. Par contre, pour se prémunir d'une aspiration systématique de son fonds (qui peut aller jusqu'à l'indexation de documents soumis à des droits d'auteurs), vous pouvez dériver les requêtes en provenance de ces robots vers une page unique.
Le contenu de la ressource File://robots.htm peut contenir un texte descriptif le plus complet possible de votre fonds, seule cette page sera indexée par le robot et, réciproquement, jamais elle ne sera visualisée par les internautes.
Si vous souhaitez seulement "diminuer" l'impact de l'indexation par les robots sur votre serveur, vous pouvez les temporiser (code T).
Le fichier robots.txt
Le filtrage et les directives fournies aux robots peuvent être tout à fait complémentaires. Il suffit que la ressource "File://robots.txt" existe pour indiquer à un robot d'indexation ce qui est interdit / autorisé.
Le fichier robots.htm
Un robot (avec un code filtrage R et non T) reçoit systématiquement la page "robots.htm". Il peut être intéressant d'y décrire votre site afin qu'un internaute qui effectue une recherche via un moteur (exemple : Qwant, Google) identifie votre site.
Accès sécurisé
Kentika supporte les accès en SSL. Pour les activer, vous devez obtenir un certificat que vous placez ensuite dans le dossier de l'application.
Détection avancée des robots
Un robot, qu'il soit d'indexation ou de piratage, a pour caractéristique de ne jamais renvoyer les cookies d'identification. Aussi, si un nombre significatif de requêtes émane de la même adresse IP mais avec des identifiants temporaires différents, il y a de fortes chances pour derrière cette adresse ce soit un robot qui opère. Un mécanisme de détection est mis en place. Il se déclenche automatiquement une fois par nuit et peut être programmé en batch pour une fréquence plus élevée (Script : PR_Add2Robots). Pour que son fonctionnement soit effectif, il suffit que soit renseigné le paramètre "WbFI". Valeur suggérée : 20.
Il est également possible (option recommandée) de forcer l'acceptation des cookies. En effet, en général, les robots ne les renvoyant pas, cela permet de leur interdire l'entrée dans le site.
Une nouvelle fonction "Add2Robots" permet également de forcer la déclaration de l'adresse IP de l'internaute comme robot.
Suppression de robots au delà d'un certain délai
Le nombre de robots détectés automatiquement peut augmenter de manière significative alors qu'un certain nombre d'entre eux ne viennent que sur une courte période tenter une entrée dans le site. Depuis la version 4.1.2 un mécanisme de purge automatique est activé. Les adresses blacklistées sont supprimées du filtrage au delà d'un certain nombre de jours d'inactivité (365 par défaut, peut être modifié via le paramètre "WxFD").
Powered by KENTIKA Atomic - © Kentika 2025 tous droits réservés - Mentions légales