 +33 4 78 17 21 16
+33 4 78 17 21 16-


- Accueil
- |
-
 L'information à 360°
L'information à 360°
- |
- Solutions
- |
- Services
- |
- Clients
- |
- Société
- |
- Actualités
6 La navigation dans le manuel de Kentika est réservée aux utilisateurs identifiés
Gestion des fils RSS
Appartenance & droits
#RSS ; Kentika Press
Gestion des fils RSS
avec le nouvel aggrégateur intégré
Depuis la v2.3, Kentika intègre un aggrégateur RSS optimisé pour l'insertion d'articles issus de fils RSS.
Développé spécifiquement pour Kentika Press, il peut cependant être utilisé indépendamment et est inclus dans le kit Atomic.
L'aggrégateur est disponible depuis la version 2.3, mais les réglages depuis le Web ne sont inclus que depuis la v2.4.
Paramétrage des rubriques
Les fils RSS doivent désormais être rattachés à des références. Pour pouvoir relever les fils RSS, un certains nombre de rubriques doivent être créées sur les références. Certaines sont obligatoires, d'autres permettent d'affiner la relève des fils.
Les rubriques liées aux fils RSS sont les suivantes :
| Nom de rubrique | Code rubrique | Type | Réglages supplémentaires |
| *Intitulé du fil | KP_RSS_Lib | Valeur (format libre) | Valeur multiple |
|
*URL du fil |
KP_RSS_URL | URL | Valeur multiple, liée à KP$_RSS_Lib |
| Thème par défaut | KP$_THE | Code (valeur des thèmes KP) | Valeur multiple, liée à KP$_RSS_Lib |
| *Profil de conservation | KP$_rPC |
Code (valeur du profil de conservation |
|
| Filtre d'import | KP$_rFI | Valeur (format libre) ou Code |
Attention : Les libellés des rubriques sont fournis à titre indicatif, mais les codes doivent impérativement correspondre à ceux indiqués dans le tableau.
Les rubriques dont les intitulés sont en gras précédés d'une étoile doivent impérativement être présentes et renseignées pour la relève des fils de la référence. Les autres sont optionnelles.
Le thème par défaut permet de renseigner un thème qui sera assigné aux articles lorsqu'ils seront intégrés à la base manuellement. Le filtre d'import permet de définir un filtre d'import différent du filtre par défaut pour l'intégration de fils aux formats particuliers dans la base.
Relève de fils
La relève des fils s'opère grâce au script "Ascript_KP_Batch_Load_RSS", qui contient simplement un appel à la méthode "KP_Batch_Load_RSS".
La relève des fils demande beaucoup de ressources à la base et peut prendre du temps si de nombreux fils doivent être relevés. Il est donc conseillé de programmer le script pour s'exécuter en batch une fois par jour en-dehors des horaires de bureau.
Astuce : Il est possible d'exécuter ce script depuis le menu Exploitation du client riche, ou en cliquant sur le bouton "Relever tous les fils actifs" depuis le paramétrage web. Attention cependant, ceci risque de produire de forts ralentissements sur la base ! À utiliser en cas extrêmes uniquement !
Astuce 2 : La partie qui est consommatrice en temps et en ressource est en fait l'extraction des mots-clés depuis le thésaurus dans le corps des articles relevés. En réduisant la branche du thésaurus pour limiter le nombre de descripteurs sur lesquels chercher, le temps de relève peut être drastiquement réduit. Il est même possible de complètement supprimer cette extraction de mots-clés en ajoutant un paramètre XML noEXTRACT=on dans la variable Tattributs avant exécution du script de relève (voir avec l'équipe Kentika si cela peut vous intéresser).
Le profil de conservation
Si une référence est paramétrée sans profil de conservation, les fils RSS associés ne seront pas relevés ! Afin de comprendre la raison pour laquelle le profil de conservation est nécessaire et de comprendre comment le paramétrer correctement, voici quelques explications sur le fonctionnement de l'aggrégateur (pour des informations plus poussées, voir plus bas) :
Lorsque Kentika relève les fils RSS, il stocke tous les articles trouvés dans une table temporaire. La fois suivante, il compare les articles qui se trouvent dans les fils RSS avec ceux qui sont déjà dans la table temporaire puis n'importe que les articles qui ne se trouvaient pas encore dans cette table.
Le problème est que certains fils sont très prolifiques, et que conserver tous les articles gonfle la base inutilement. Ils sont donc supprimés en fonction du profil de conservation de la référence à laquelle le fil est rattaché.
Il faut donc régler le profil de conservation sur une durée limitée (et non sur "Toujours"), mais suffisamment longue pour que les articles qui se trouvent toujours dans le fil RSS en ligne soient également présents dans la base.
Exemple : Le fil "A la une" du monde ne contient que des articles du jour. Si l'on n'a que ce fil réglé pour Le Monde, on peut donc régler le profil de conservation à "Une journée" (ou "trois jours" pour être sûr). Par contre, si on ajoute ensuite le fil "Études sup", qui, à l'heure où cette page est écrite, contient des articles datant d'un mois en arrière, lorsque Kentika relèvera ce fil, il trouvera des articles datant d'un mois mais qui ne sont pas présents dans la table temporaire (puisqu'ils auront été supprimés par le profil de conservation de quelques jours). Il les importera donc de nouveau et les présentera comme étant "nouveaux". Il vaut mieux changer le profil de conservation à quelques mois.
Astuce technique : Il est possible de demander à Kentika d'effectuer la relève de tous les fils, même s'ils n'ont pas de profil de conservation : Il suffit d'exécuter la méthode KP_Batch_Load_RSS avec le paramètre http "rssall" égal à "on".
Par défaut, le profil de conservation est transféré au document lorsqu'un article RSS est intégré à la base (voir plus bas). Il est cependant possible de modifier le filtre d'import RSS pour modifier le profil de conservation intégré par défaut à l'enregistrement des articles (voir plus bas également).
Intégration des articles
Une fois les fils relevés, les articles sont accessibles sur le portail, sur la liste par défaut. Il est possible de créer des dossiers sur les fils RSS en créant des requêtes portant sur la table RSS pour afficher les articles en profitant de toutes les options de tri/recherche de Kentika.
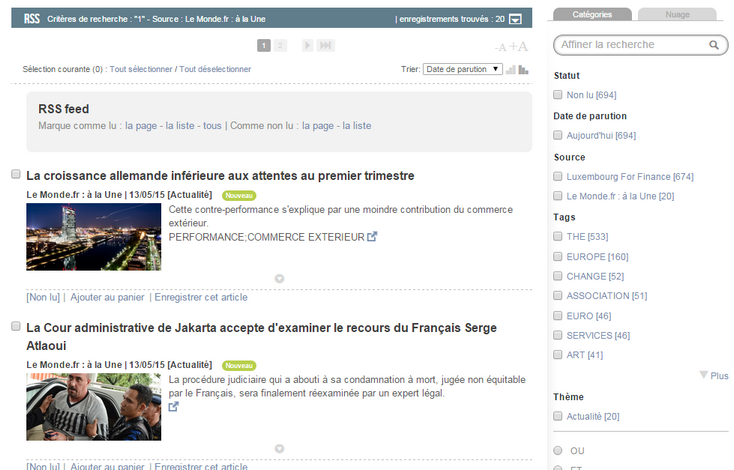
Affichage de la liste des derniers fils RSS
Les articles sont ensuite affichés dans la liste par défaut du portail Atomic. Certains composants présents par défaut permettent de gérer ces fils :
- Des options (invisibles à l'affichage) en tête de page (toPGeneric_Head > KP_RSS_...) permettent de passer automatiquement un article au statut "lu" lorsque la notice est ouverte, ou toute la page lorsque l'on arrive en bas de page ou que l'on clique pour ouvrir la page suivante de la liste.
- Une option en tête de liste (ListRecord_ListTop > ListRecord_Insert_RSS) permet de modifier le statut lu/non lu de tous les articles de la liste/page courante d'un seul coup.
- Une option en pied d'article (ListRecord_List_Foot > ListRecord_RSS2Doc) permet d'intégrer directement un article à la base (en utilisant soit le filtre par défaut, soit le filtre défini dans la rubrique KP$_rFI).
- Une option en pied d'article (ListRecord_List_Foot > ListRecord_RSSRead) permet de changer le statut lu/non lu d'un article.
Note : Le statut "lu/non lu" a pour vocation de s'appliquer aux gestionnaires qui effectuent un tri sur les articles RSS pour les intégrer dans la base. Ils sont donc communs pour toute la base, et non par utilisateur. Les utilisateurs non gestionnaires n'ont par défaut pas accès à ce statut.
Pour plus d'informations sur ces composants, se rapporter au catalogue des composants.
Lorsqu'un article est intégré, il est automatiquement converti de fil RSS en document, selon les règles définies dans le filtre d'import, et l'article dans la page est remplacé par le document, qui peut être immédiatement modifié si l'utilisateur a les droits appropriés.
Le filtre d'import
Comme mentionné plus haut, lorsqu'un article est intégré dans Kentika, il est transformé en document via un filtre d'import classique. Par défaut, toutes les bases Kentika contiennent le filtre "KP_RSS", qui est celui qui est utilisé par défaut.
Depuis le kit v4.2, le filtre par défaut a pour code "KP_RSS*", ce qui permet de le dériver avec le code "KP_RSS", qui sera utilisé par défaut, sans risquer de perdre ses modifications sur les futures mises-à-jour. Avant cette version, pour dériver le kit, il faut utiliser la rubrique "Filtre d'import" mentionnée plus haut.
Il est cependant possible de définir un filtre à utiliser pour chaque référence sur laquelle un fil est défini, si besoin. Pour cela, il faut utiliser la rubrique "KP$_rFI" sur la référence. Cette rubrique doit avoir pour code le code du filtre d'import.
Utiliser un fil spécifique peut permettre de traiter des fils RSS dont la structure est inhabituelle, ou de gérer une structure Kentika inhabituelle (par exemple s'il faut mettre le titre de l'article dans un champ autre que le titre des notices Kentika.)
Cela peut également permettre de modifier le profil de conservation qui sera attribué par défaut à l'intégration de l'article en notice. En effet, par défaut, le filtre reprend le profil de conservation de la référence.
Exemple : Pour que tous les articles soient enregistrés avec un profil de conservation à "Toujours", il suffit de rajouter la ligne suivante dans le "script après création fiche" du filtre d'import :
Field_Set("KP$_dPC";"Z")
Paramétrage avancé
L'aggrégateur intégré à Kentika permet de faire un pré-traitement des données, avec une extraction de mots-clés. Les paramétrages pour ceci ainsi que d'autres paramètres pour les fils RSS sont disponibles sur le portail.
Pour y accéder, il faut passer soit par le supermenu dédié, soit accéder à l'URL "KP_settings.htm" et descendre jusqu'à la partie concernant les fils RSS :
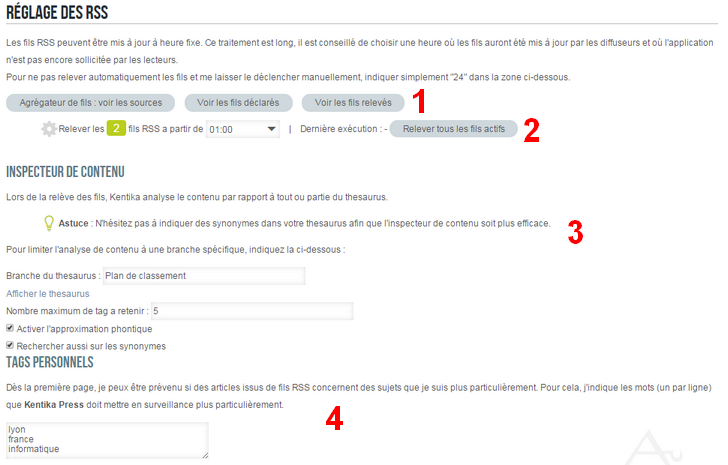
Paramétrage Web des fils RSS
La zone 1 permet d'accéder aux listes des références ayant des fils RSS déclarés. La zone 2 permet de régler directement le script AScript_KP_Batch_Load_RSS (voir plus haut).
L'inspecteur de contenu (3 ) permet d'extraire automatiquement des mots du texte et de les passer en mots-clés. Cela permet entre autres de trier ensuite les articles RSS par mot-clé dans la catégorisation en liste.
Par défaut, Kentika cherche les mots issus du thésaurus et présents dans l'article du fil RSS. Il est cependant possible d'affiner la recherche en précisant une branche spécifique du thésaurus (ou un terme parmi les termes spécifiques duquel il faudra chercher) à partir de laquelle les mots seront recherchés dans les fils RSS.
Enfin, les tags personnels (4 ) permettent d'alimenter une rubrique KP_pTAG (si elle existe) de la fiche personne (valeur libre multivaluée) avec des mots spécifiques à rechercher. Cela permet de créer une requête affichant les articles contenant ces mots ou expressions.
Note : Cela n'est pas spécifique aux fils RSS : La requête doit être créée par les gestionnaires de la base, et peut s'appliquer à n'importe quel champ de n'importe quel type d'enregistrement.
Pour paramétrer la requête, il faut utiliser la formule suivante :
CHERCHER([personne];[personne]identifiant=AIdent)
$0:=Valeur_rubrique("KP_pTAG";"sep= / ;conf=off")
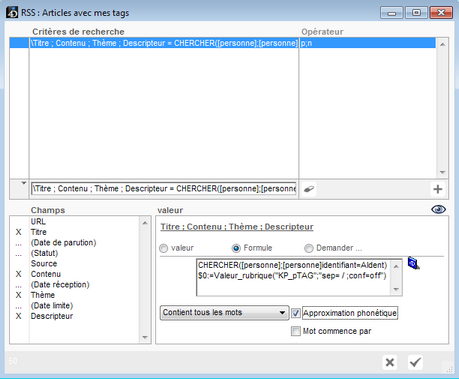
Exemple de paramétrage de dossier portant sur les fils RSS et contenantles tags de l'utilisateur courant.
Un peu de technique...
Pour ceux qui souhaitent aller plus loin, voici quelques informations sur le fonctionnement de l'aggrégateur de fils RSS.
Lorsque Kentika relève les fils RSS, une boucle est effectuée sur chaque valeur de la rubrique KP_RSS_URL. Une vérification est effectuée sur le profil de conservation, puis un fichier est créé dans le dossier AKTemp/Signature_S/Temp/, dans lequel est mis le contenu du fil.
Chaque item du fil est ensuite dédoublonné avec les articles déjà présents dans la table [RSS_temp], en se basant sur l'URL de l'article. Si l'article n'existe pas, un nouvel enregsitrement est créé dans la table [RSS_temp] avec les informations extraites du fil (et enrichies par Kentika). Le champ [RSS_Temp]xml_content le code exact complet trouvé dans le fichier importé dans AKTemp.
Les enregistrements de la table [RSS_Temp] ayant dépassé leur délai de conservation sont ensuite supprimés, puis l'extraction des termes du thésaurus est effectuée.
La table [RSS_Temp] contient un champ "statut", qui est un chiffre donnant le statut de l'item au cours de sa vie. Ce champ peut prendre les valeurs suivante :
- 0 : Importé
- 1 : Non lu
- 2 : Lu
- 8 : Intégré dans la base
- 9 : À purger
Powered by KENTIKA Atomic - © Kentika 2025 tous droits réservés - Mentions légales