 +33 4 78 17 21 16
+33 4 78 17 21 16-


- Accueil
- |
-
 L'information à 360°
L'information à 360°
- |
- Solutions
- |
- Services
- |
- Clients
- |
- Société
- |
- Actualités
6 La navigation dans le manuel de Kentika est réservée aux utilisateurs identifiés
Document Engine version 2 : installation, fonctionnement
Appartenance & droits
Document Engine version 2 : installation, fonctionnement, paramétrage
Installation
Kentika Document Engine est une application fonctionnant en mode service et n'a pour fonction que de répondre aux sollicitations de Kentika. Le service doit se lancer en automatique lors du démarrage du système. L'index est généré dans le répertoire (luceneindex2/(signature de la base)) contenant les archives (ALGEDIM). Kentika et "Kentika Document Engine" communiquent sur le port 9001. Ce dernier doit donc rester ouvert (à vérifier dans le pare-feu).
Cas d'une mise à jour
Dans le cas d'une montée de version, l'ancien répertoire (luceneindex/(signature de la base)) peut être supprimé. Alors que la version 1 nécessitait de n'indexer que des textes sans accents, une étape intermédiaire était nécessaire (calcul des textes sans accents) et des répertoires sous "(signature de la base)_Tx" étaient créés. Ces répertoires ne sont plus utiles avec la version 2. Après vérification de la bonne installation, ils peuvent être supprimés.
L'index doit être recalculé dans tous les cas. Si vous personnalisez les paramètres, il est nécessaire de les modifier avant de recalculer l'index.
KDE2 sait maintenant générer des "PDF/A". Pour que les pdf générés soient dans ce nouveau format, il est nécessaire de créer un paramètre "AaPA" avec la valeur "1".
KDE2 permet d'exploiter, outre ses propres règles, les approximations phonétiques de Kentika. Pour cela, il est nécessaire de cocher l'option "Activer l'autocompletion" et de lancer le script "Dico_Repair".
L'index de KDE2 est beaucoup plus sophistiqué que celui de KDE1, le temps de calcul est donc allongé. Le temps de traitement se situe aux alentours de 24h pour 300 000 pages de texte seul. Il est donc important de bien choisir la période à laquelle l'opération sera réalisée (exemple : pendant un week-end).
Fonctionnement
L'indexation des fichiers s'effectue en différentes étapes :
- extraction du texte contenu dans les documents bureautique ou pdf
- identification de la langue dominante (français ou autre langue)
- indexation en mode "lemmatisé" et "termes exactes" (si l'option est cochée en paramétrage).
- remontée des statuts vers la base de données
Si l'indexation full text concerne également les métadonnées : à chaque mise à jour d'une fiche est recalculé un fichier (dans ALGEDIM : répertoires commençant par la lettre "M") contenant les rubriques désignées en paramétrage et indexation suivant le même processus que celui décrit ci-dessus.
L'indexation des métadonnées est particulièrement utiles lorsque l'on souhaite permettre des recherches multi-critères autorisant les même opérateurs que ceux utilisés pour les fichiers. Si la base est constituées de textes saisis en gestion de contenu, il peut être intéressant de proposer ces recherches élaborées.
Lemmatisation
La lemmatisation des termes consiste à les réduire à la partie significative commune. Exemple : "formateur" ; "formatrice" ; "formation"... se rapporte à la même notion. Ceci est particulièrement utile pour éviter des "silence" mais peut également entrainer du bruit dans les recherche. D'où l'utilité de gérer également la notion de "terme exact" afin de permettre de cerner au mieux les informations recherchées. Les terminaisons de fin de mots prises en compte sont : "issement, issant, ement, ficatrice, ficateur, catrice, cateur, atrice, ateur, trice, ième, teuse, teur, euse, ère, ive, folle, molle, nnelle, nnel, ète, ique, esse, inage, isation, isateur, ation, ition". Cette fonction peut être désactivée lors du paramétrage (option : "UseCustomStemFilterEnds"). De même, les singuliers / pluriels sont traités par défaut et peuvent être désactivés par paramétrage (option : "UseCustomStemFilter").
Mots vides (ou stopwords en anglais)
Un mot vide n'est pas porteur de sens. Aussi, il est intéressant de pouvoir les exclure, à l'indexation et lors des recherches.
Certains mots sont vides dans certains contexte, porteur de sens dans d'autres. Le mot "est" lorsqu'il est la conjugaison du verbe "être" est un mot vide ; lorsqu'il indique un point cardinal, il est porteur de sens.
La liste est différente entre le français et l'anglais. En effet, "the" est vide en anglais mais "thé" est une boisson en français.
Elisions
L'élision consiste à remplacer la voyelle finale d'un mot par une apostrophe lorsqu'il est placé devant un mot commençant par une voyelle ou un h muet. Ainsi "puisque" et "puisqu" doivent être considérés comme des termes identiques.
Approximations phonétiques
Particulièrement utile pour détecter les erreurs de frappe ou les incertitudes sur l'écriture de certains mots, la fonction peut être activée par défaut lors de la création d'un masque de recherche ou laissée à l'appréciation de l'utilisateur. Cette deuxième option, si elle requiert une action volontaire de la part de l'utilisateur, est préférable pour éviter des résultats qui pourraient le surprendre.
Paramétrage
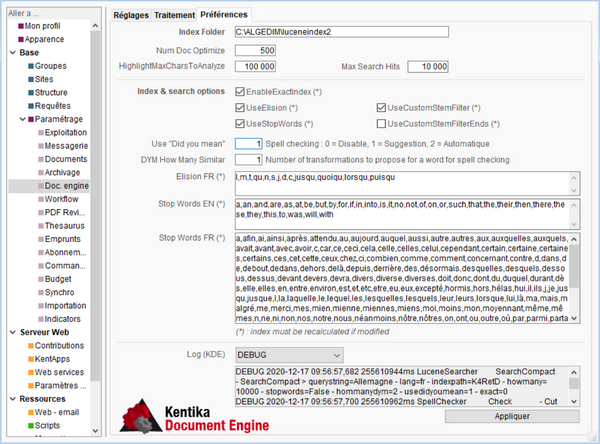
- Index folder : chemin d'accès du répertoire contenant les index
- Num doc optimize : optimisation de l'index après l'ajout de xxx documents.
- highlight max char to analyse : permet de limiter la langueur du texte à analyser lors du calcul du texte affiché en aperçu dans une liste. En fixant une limite haute, les performances sont dégradées ; trop basse, des expressions dans leur contexte ne seraient pas présentées.
- Max search hits : limite la recherche au xxx premiers documents trouvés.
- Enable exact index : créé un double index (plus consommateur en temps d'indexation, possibilité de faire des recherches précises).
- Use ellision ; stopwords ; custom stem filter ; custom stem filter end : voir ci-dessus.
- Use did you mean : approximation phonétique automatique, sugestion (recommandé).
- How manybsimilar : niveau de précision de l'approximation.
- Log KDE : à activer en cas de recherche de panne uniquement.
Appliquer : envoie l'ordre d'arrêter le service KDE, effectue la mise à jour du fichier de paramétrage et relance le service. Recalculer l'index (onglet : traitement) après mise à jour d'une option figurant avec (*).
Powered by KENTIKA Atomic - © Kentika 2025 tous droits réservés - Mentions légales