 +33 4 78 17 21 16
+33 4 78 17 21 16-


- Accueil
- |
-
 L'information à 360°
L'information à 360°
- |
- Solutions
- |
- Services
- |
- Clients
- |
- Société
- |
- Actualités
6 La navigation dans le manuel de Kentika est réservée aux utilisateurs identifiés
KAAT - KDE (Kentika Document Engine) : utilisation de l'API
Appartenance & droits
KDE : installer, utiliser les APIs
Les APIs de KDE permettent de convertir des documents bureautiques en pdf, html ou text et d'océriser un fichier pdf image afin de pouvoir en indexer le contenu, extraire des informations ou encore d'optimiser la place occupée sur un disque.
Utiliser l'installeur (RTSLuceneInstaller115.msi) pour installer KDE. Il sera probablement nécessaire de déclarer de nouvelles règles au niveau du pare-feu du serveur afin que les requêtes vers KDE ne soient pas bloquées. L'API de KDE et votre application communiqueront en http (web service REST) sur le port 9001.

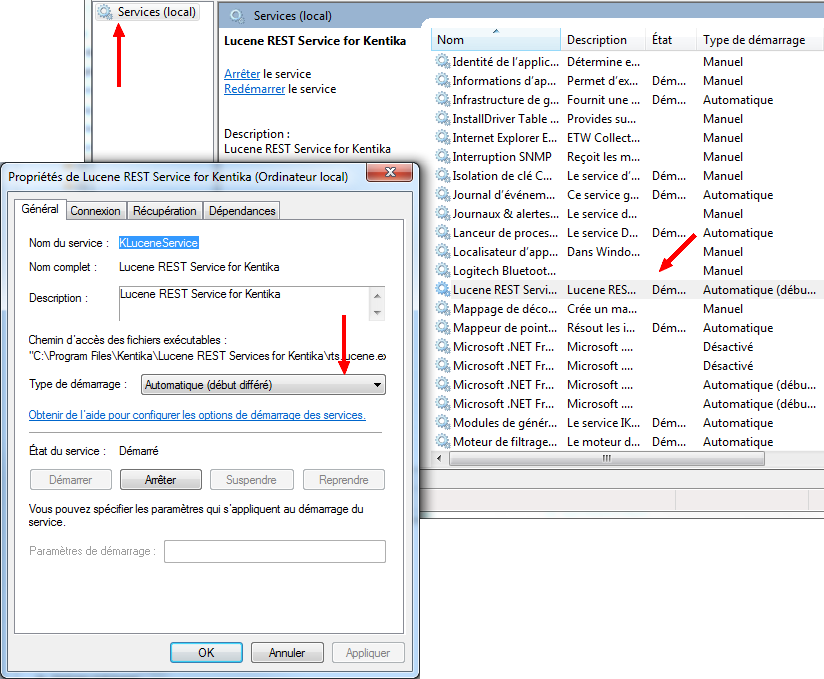
Démarrer le service
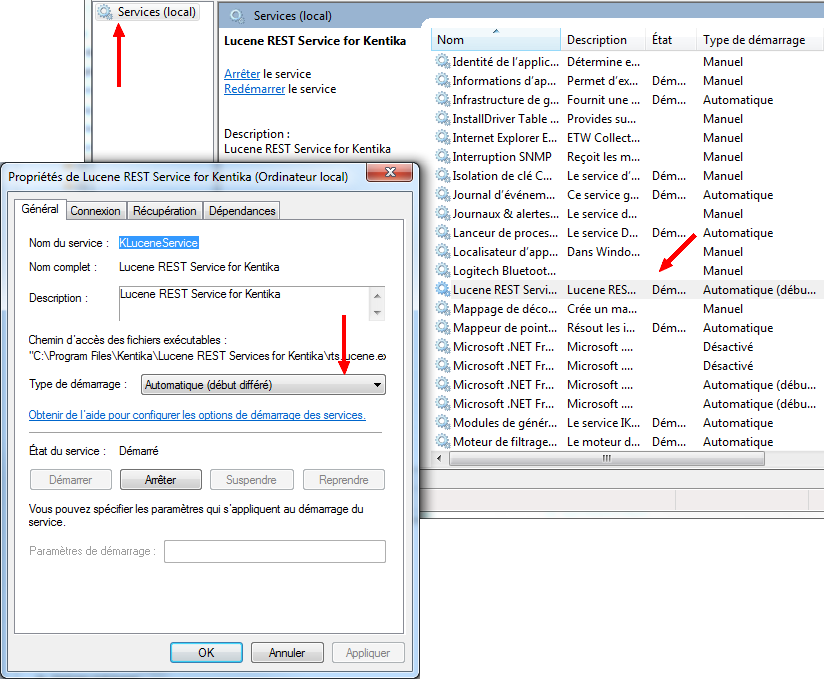
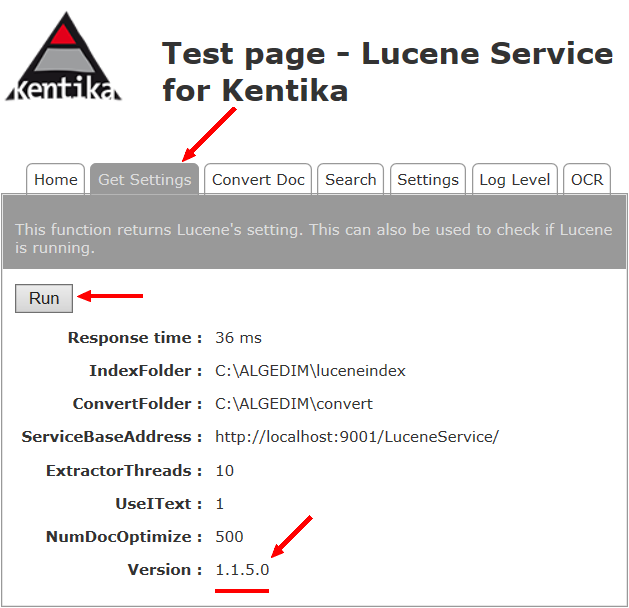
Vérifier le fonctionnement en utilisant la page de test.
Dans le répertoire qui vient d'être créé sur le disque, ouvrir "Lucene REST Services for Kentika ", ouvrir la page "TestPage.html " avec Internet Explorer .
En pied de page, cliquer sur "Autoriser le contenu bloqué".

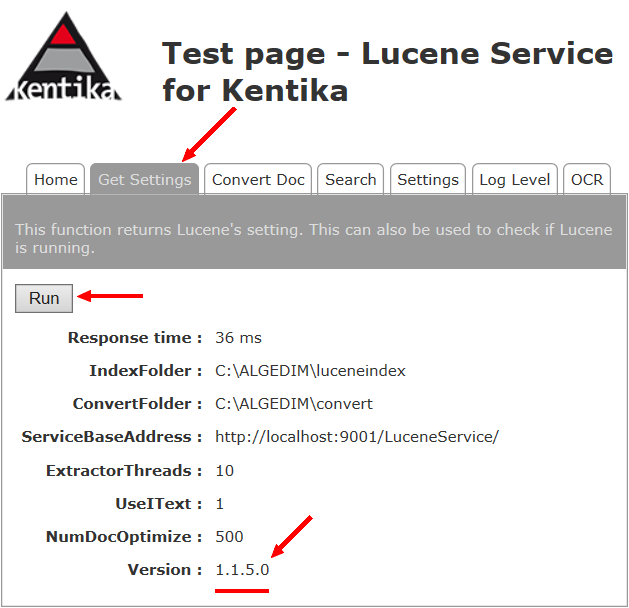
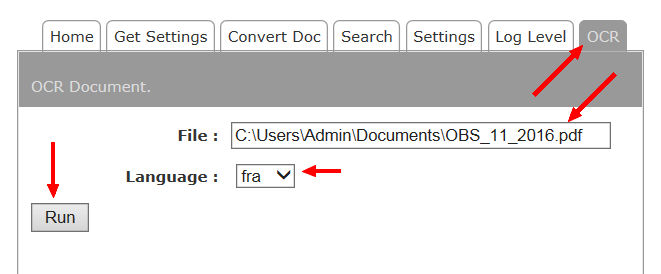
NB : cette page vous permet de tester les convertisseurs et l'OCR proposés par KDE en se rendant sur le dernier onglet :
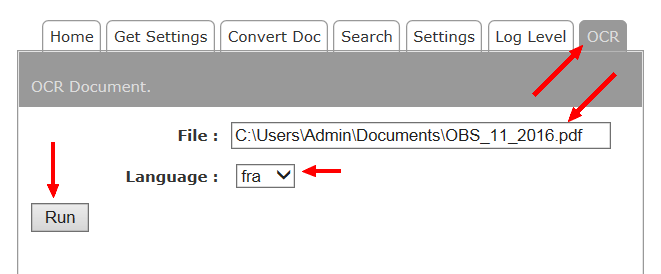
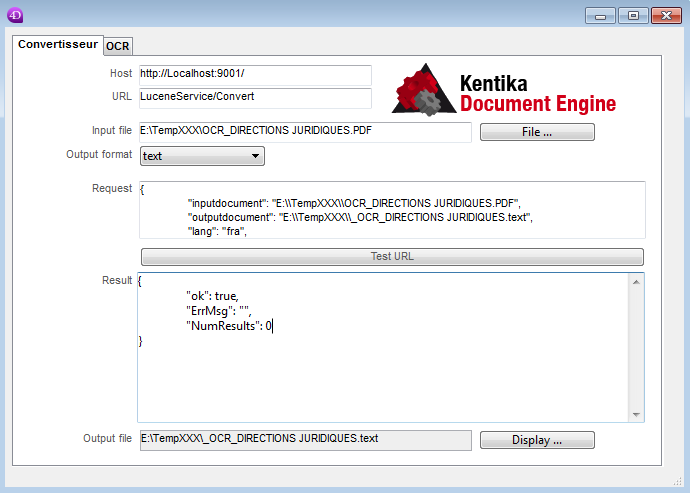
Après exécution, un fichier par "_" sera créé dans le même répertoire.
Description de l'API
Host : Localhost
Numéro de port : 9001
Convertir un fichier
URL : LuceneService/Convert
Paramètres
inputdocument : chemin d'accès complet au fichier à convertir
outputdocument : chemin d'accès complet du fichier à produire
outputformat : html ou pdf ou text
Exemple
{
"inputdocument": "E:\\TempXXX\\DIRECTIONS JURIDIQUES.PDF",
"outputdocument": "E:\\TempXXX\\_DIRECTIONS JURIDIQUES.html",
"outputformat": "html"
}
Fonctionnement
Lors de l'appel au serveur, ce dernier prend en compte la demande, accuse réception et débute le traitement.
{
"ok": true,
"ErrMsg": "",
"NumResults": 0
}
Pour savoir si la conversion est terminée, il suffit de tester la présence du fichier spécifié en "outputdocument". Suivant la taille et la complexité du fichier en entrée, ce temps peut être plus ou moins long. L'extraction du texte d'un document bureautique sera rapide (2 à 3 secondes pour document .docx de 100 pages) ; la conversion d'un fichier pdf complexe en html peut être relativement longue (chaque élément non textuel des pages peut donner lieu à un fichier image).
Lorsque le convertisseur commence, il créé un premier fichier de même nom que celui spécifié pour la sortie préfixé par _. Lorsque le traitement est terminé, ce fichier est copié avec le nom spécifié. Si un fichier ne comporte aucun texte ou si la conversion ne peut aboutir, le fichier définitif ne sera pas créé.
Dans le cas d'une conversion html, un dossier de même nom que le fichier à créer est automatiquement créé et il comportera les images.
Dans le cas d'une conversion html en vue d'une diffusion web, il est intéressant de créer le fichier dans le répertoire racine du serveur afin que les images soient automatiquement servies par le serveur http.
Océriser un fichier pdf
URL : LuceneService/OCR
Paramètres
inputdocument : chemin d'accès complet au fichier à convertir
outputdocument : chemin d'accès complet du fichier à produire
lang : fra pour français ; eng pour english (liste disponible ici)
Exemple
{
"inputdocument": "E:\\TempXXX\\DIRECTIONS JURIDIQUES.PDF",
"outputdocument": "E:\\TempXXX\\_DIRECTIONS JURIDIQUES.html",
"outputformat": "html"
}
Fonctionnement
Lors de l'appel au serveur, ce dernier prend en compte la demande, accuse réception et débute le traitement.
{
"ok": true,
"ErrMsg": "",
"NumResults": 0
}
Pour savoir si la conversion est terminée, il suffit de tester la présence du fichier spécifié en "outputdocument".
L'OCR utilisé par KDE est Tesseract.
KDE et 4D
Afin de faciliter l'utilisation de l'API de KDE, une application en 4D v16 est disponible (mode interprété, code ouvert). Il suffit de copier le contenu des scripts et de les coller dans votre application.
Pour générer un index plein texte à partir du contenu de fichiers bureautiques, il sufft de convertir ces fichiers et d'alimenter un champ texte dans votre base 4D avec un index mot-clé. Pour une exploitation plus poussée exploitant des opérateurs de proximité, il est recommandé d'utiliser KAAT (Kentika As A Toolbox.
<WR_Val_EN>
KDE : install, use APIs
KDE APIs allow you to convert office documents into pdf, html or text and to use an image pdf file so you can index the content, extract information or optimize the space occupied on a disk.
Use the installer (RTSLuceneInstaller115.msi) to install KDE. It will probably be necessary to declare new rules at the server firewall so that requests to KDE are not blocked. The KDE API and your application will communicate in http (web service REST) on port 9001.
Start the service
Check the operation using the test page.
In the directory that has just been created on the disk, open "Lucene REST Services for Kentika ", open the page "TestPage.html" with Internet Explorer .
At the bottom of the page, click on "Allow blocked content (Autoriser le contenu bloqué)".

NB: this page allows you to test the converters and OCR proposed by KDE by going to the last tab:
After execution, a file with "_" will be created in the same directory.
Description of the API
Host : Localhost
Numéro de port : 9001
Convert a file
URL : LuceneService/Convert
Paramètres
inputdocument : full path to the file to convert
outputdocument : full path to the file to produce
outputformat : html or pdf or text
Example
{
"inputdocument": "E:\\TempXXX\\DIRECTIONS JURIDIQUES.PDF",
"outputdocument": "E:\\TempXXX\\_DIRECTIONS JURIDIQUES.html",
"outputformat": "html"
}
Operation
During the call to the server, the latter takes into account the request, acknowledges receipt and starts processing.
{
"ok": true,
"ErrMsg": "",
"NumResults": 0
}
To know if the conversion is complete, just test the presence of the file specified in "outputdocument". Depending on the size and complexity of the input file, this time may be longer or shorter. The extraction of the text from an office document will be fast (2 to 3 seconds for a .docx document of 100 pages); the conversion of a complex pdf file into html can be relatively long (each non-textual element of the pages can give rise to an image file).
When the converter starts, it creates a first file with the same name as the one specified for the output prefixed with _. When processing is complete, this file is copied with the specified name. If a file contains no text or if the conversion can not succeed, the final file will not be created.
In the case of a html conversion, a folder with the same name as the file to be created is automatically created and it will include the images.
In the case of a html conversion for a webcast, it is interesting to create the file in the root directory of the server so that the images are automatically served by the http server.
OCR : pdf file
URL : LuceneService/OCR
Settings
inputdocument : full path to the file to convert
outputdocument : full path to the file to produce
lang : eng for english ; fra pour français (list available)
Example
{
"inputdocument": "E:\\TempXXX\\DIRECTIONS JURIDIQUES.PDF",
"outputdocument": "E:\\TempXXX\\_DIRECTIONS JURIDIQUES.html",
"outputformat": "html"
}
Operation
During the call to the server, the latter takes into account the request, acknowledges receipt and starts processing.
{
"ok": true,
"ErrMsg": "",
"NumResults": 0
}
To know if the conversion is complete, just test the presence of the file specified in "outputdocument".
The OCR used by KDE is Tesseract.
KDE and 4D
To facilitate the use of the KDE API, a 4D v16 application is available (interpreted mode, open code). Just copy the contents of the scripts and paste them into your application.
To generate a full-text index from the contents of office files, simply convert these files and feed a text field into your 4D database with a keyword index. For further operation using local operators, it is recommended to use KAAT (Kentika As A Toolbox.
</WR_Val_EN>
Powered by KENTIKA Atomic - © Kentika 2025 tous droits réservés - Mentions légales