 +33 4 78 17 21 16
+33 4 78 17 21 16-


- Accueil
- |
-
 L'information à 360°
L'information à 360°
- |
- Solutions
- |
- Services
- |
- Clients
- |
- Société
- |
- Actualités
6 La navigation dans le manuel de Kentika est réservée aux utilisateurs identifiés
Paramétrage - Exploitation
Appartenance & droits
Exploitation
Les paramètres d'exploitation permettent d'affiner le comportement de certains index de recherche et de définir les langues dans lesquelles la base de données doit pouvoir être utilisée.
Ecran de saisie des paramètres d'exploitation
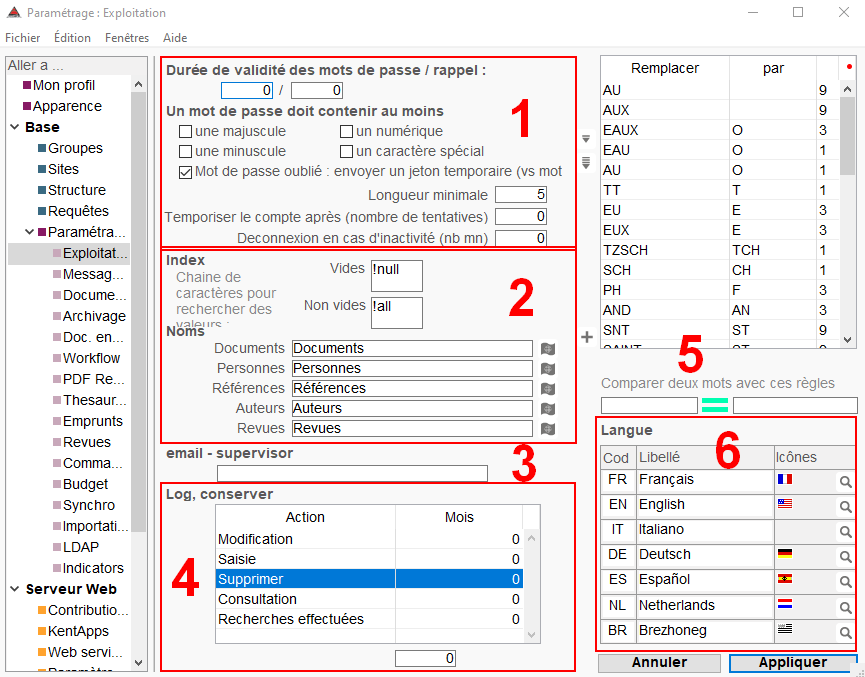
Gestion des mots de passe
1 Les mots de passe peuvent être paramétrés depuis la v3.1 pour répondre aux recommandations du RGPD. Il existe différentes options :
Durée de validité / Rappel : Indiquez en premier, en nombre de jours, la durée de validité des mots de passe. Au-delà de ce délai, si l'utilisateur n'a pas modifié son mot de passe ou si l'administrateur n'a pas modifié sa date de mise à jour, la connexion à Kentika n'est plus autorisée. En second, indiquez le nombre de jours à partir desquels l'utilisateur recevra un message lorsqu'il se connecte Kentika, avant que son mot de passe arrive à expiration.
Complexité : Les quatre boîtes à cocher permettent de définir la complexité des mots de passe demandés. Chaque mot de passe entré dans Kentika doit contenir au moins un caractère de chaque type coché.
Mot de passe oublié... : Historiquement, lorsqu'un utilisateur demandait depuis le portail à recevoir son mot de passe oublié, Kentika lui envoyait un email avec le mot de passe en clair. Lorsque cette case est cochée, Kentika envoie à la place un lien, valide durant la journée, pour que l'utilisateur puisse se créer un nouveau mot de passe.
Longueur minimale : Lié à la complexité des mots de passe, ce champ permet de fixer la longueur minimale exigée des mots de passe.
Temporiser le compte... : Ce paramètre permet d'éviter les attaques "brute force". Vous pouvez définir au bout de combien de fois un utilisateur qui se trompe dans son mot de passe est bloqué pour 5 minutes.
Déconnexion en cas d'inactivité : Avec le kit 3.1, cette option permet de déconnecter automatiquement un utilisateur qui est inactif sur le portail pendant le nombre de minutes défini.
Base de donnée
Index
2 Si vous voulez avoir la possibilité de rechercher dans la base de données tous les enregistrements qui auraient une rubrique non renseignée, vous indiquez ici la chaîne de caractères qui devra être utilisée pour effectuer cette recherche. Vous pouvez en saisir plusieurs (une par ligne) ; elles auront alors le même comportement.
Vous pouvez régler le paramètre suivant pour les champs qui ont au moins une valeur saisie.
Avec les chaines de recherches de valeurs vides et non vides suivantes :

on peut exprimer ses requêtes comme suit :

Lignes 1 et 2 : toutes les fiches qui n'ont pas d'auteur ; lignes 3 et 4 : toutes les fiches qui ont au moins un descripteur
email - supervisor
4 Ce champ permet de définir une adresse email à laquelle un email sera adressé lorsque la base détecte une anomalie de fonctionnement. Parmis les vérifications qui sont effectuées, on trouve les informations suivantes :
- Nombre de fiches dans la table des logs
- Paramétrage correct de la sauvegarde et du journal
- Mails non envoyés, pouvant bloquer la DSI, les produits KP, ou d'autres fonctionnalités
- Trop de guests sur le portail (présence probable de robots)
Nettoyage des logs
Depuis la v3.1, Kentika propose une option de nettoyage automatique des logs. Ce nettoyage est fait tous les soirs, et supprime les logs plus anciens que le nombre de mois indiqués. Les logs sont auparavant archivés dans un dossier ArchiveLOG, dans le dossier AKTemp.
Note : Les logs ne sont pas supprimés tous les jours, mais seulement lorsqu'il y en a plus de 1000 qui correspondent aux critères de suppression.
Les différentes actions correspondent aux logs de code :
Modification : 2 et 3
Saisie : 4
Supprimer : 8 et 9
Consultation : 10, 11, 100 et 101
Recherches effectuées : 21 à 29
Approximation phonétique
5 Cette fonction permet d’effectuer une recherche approchante en appliquant une approximation phonétique sur l’index uniterme.
Il s’agit d'établir des correspondances entre l’orthographe d’un mot ou d’une syllabe et sa prononciation phonétique.
Exemple : "ai" devient "è" ; "phy" devient "fi", etc. A chaque fois que l’utilisateur recherchera une valeur en saisissant "Fisicien" dans la valeur à rechercher, Kentika proposera aussi "Physicien". L'index sera égal à "fisicien".
Cet outil servira également à gérer une liste de mots vides. Un mot vide est réputé non porteur de sens et sera écarté lors des recherches.
Exemple : vous avez déclaré les articles comme mots vides (un, une, des, le, la, les... ). Si un titre contient "une vision de l'informatique", une recherche sur l'expression "la vision d'une informatique" permettra d'identifier le titre comme correspondant à la recherche.
Cette fonction n'est utile que dans le cas de la recherche et il convient de l'adapter à la nature du fonds et du public. La diversité des langues gérées dans l'application est un élément important à prendre en compte. En effet, ces règles s'appliquent sans distinction de langue (il serait trop long de devoir préciser à chaque saisie en quelle langue elle est effectuée). Si vous gérez des documents en plusieurs langues, il faut être vigilants par rapport aux règles qui pourraient se contredire.
Exemple : si vous gérez des documents en langue anglaise et que vous déclarez "the" comme mot vide, le mot "thé" en français sera alors considéré également comme mot vide et vous ne pourrez plus retrouver les documents parlant de cette boisson.
Saisie des correspondances
Dans le tableau, saisir ligne après ligne toutes les correspondances que l’on souhaite établir en cliquant sur le bouton +... :
- dans le premier pavé de saisie en bas de l’écran, saisir l’orthographe qui sera transformée phonétiquement ;
- dans le second pavé saisir la correspondance phonétique ;
- dans le troisième pavé insérer les valeurs 1, 2, 3 ou 9 correspondant à la place dans le mot où la règle de transformation doit être appliquée.
Les valeurs correspondent aux emplacements suivants :
1 : partout
2 : en début
3 : en fin
9 : mot entier
Ordre d'application
L’ordre des lignes dans le tableau est très important. Les approximations phonétiques sont appliquées suivant l'ordre de saisie des correspondances.
Exemple : vous voulez remplacer "eau" et "au" par "o" ; si vous saisissez dans l'ordre suivant : "au -> o" puis "eau -> o" ; le terme "bateau", sera transformé dans un premier temps en "bateo" puis restera tel quel car l'application ne trouvera plus la chaîne "eau" ; l'ordre correct est "eau -> o" puis "au -> o".
Vous pouvez modifier l'enchaînement des lignes en utilisant les flèches :
![]() Pour remonter la ligne sélectionnée en première position du tableau.
Pour remonter la ligne sélectionnée en première position du tableau.
![]() Pour remonter la ligne sélectionnée d'un niveau.
Pour remonter la ligne sélectionnée d'un niveau.
![]() Pour descendre la ligne sélectionnée d'un niveau.
Pour descendre la ligne sélectionnée d'un niveau.
![]() Pour descendre la ligne sélectionnée en dernière position du tableau.
Pour descendre la ligne sélectionnée en dernière position du tableau.
Vérification des règles
Vous pouvez vérifier l'application des règles d'approximation en saisissant un terme bien orthographié et un terme mal orthographié.
Si les règles d’approximation phonétique mises en place ne rendent pas les deux formes d’écriture équivalentes à la recherche, l'application affiche un signe d’inégalité entre les deux termes ou expressions :
![]()
Si les règles d’approximation phonétiques mises en place rendent les deux formes d’écriture équivalentes à la recherche, l'application affiche un signe d’égalité entre les deux termes ou expressions :
![]()
Application des règles
A la validation du paramétrage, Kentika vous signale que vous avez modifié les règles d'approximation phonétique et vous propose de recalculer les index.
Cliquez sur OK pour exécuter le recalcul ou sur Annuler pour laisser en attente si vous devez ré-intervenir sur ces règles. Le message vous sera proposé chaque fois que vous validerez le paramétrage et tant que la reconstruction des index n'aura pas été effectuée.
En architecture Client / Serveur, il est IMPERATIF qu'aucun autre poste client ne travaille sur Kentika pendant le recalcul des index.
Charger / Enregistrer
Le pop-up menu (point rouge situé en haut à droite de la zone des remplacements) permet d'enregistrer les règles définies dans un fichier externe, de manière à les charger dans un autre fichier de données, à l'aide de l'option "Charger".
Vous pouvez également charger un fichier composé à l'aide d'un éditeur de texte structuré ainsi : valeur à remplacer + tabulation + valeur de remplacement + tabulation + règle (1, 2, 3 ou 9) + retour à la ligne.
Rappel : 1 pour un remplacement partout dans le mot, 2 pour un remplacement uniquement en début de mot, 3 pour un remplacement en fin de mot et 9 pour un remplacement du mot complet.
Gestion des mots vides
Les mots vides sont des termes non significatifs (articles, pronoms, adverbes, etc.) qui ne seront pas pris en compte lors de l'indexation des champs.
Si votre fonds est constitué de documents multilingues pour lesquels vous saisissez les titres originaux, n'oubliez pas de saisir également les mots vides de chacune des langues potentielles.
Pour ajouter un mot vide, cliquez sur le bouton "+", puis :
- saisissez votre mot vide dans la première colonne ;
- ne saisissez rien dans la seconde colonne ;
- indiquez le chiffre 9 dans la dernière colonne pour préciser que cette règle de transformation s'applique au mot entier.
Si votre base de données propose des adresses avec des possibilités de recherche, pensez à vérifier que vous avez bien dans les règles ce qui concerne les dénominations de type de rue, exemples :
boulevard -> bd
blv -> bd
bvd -> bd
avenue -> av
ave -> av
square -> squ
impasse -> imp
...
Langues-langages
6 Vous pouvez gérer une interface multilingue, composée de six langues différentes qui sont par défaut le français, l'allemand, l'anglais, l'espagnol, l'italien et le néerlandais. Cela permettra à chaque utilisateur de choisir la langue dans laquelle il souhaite consulter la base.
A chaque langue sont associés un code et une icône.
Si vous souhaitez gérer une langue autre que celles proposées par défaut, il vous suffit d'en choisir une dont vous n'avez pas l'usage, et de remplacer son code (2 caractères) et son libellé (21 caractères au maximum). Pour attacher une autre icône, cliquez sur le bouton "?" et sélectionnez une icône parmi la liste proposée.
Voir : menu fichier > préférences > base > paramétrage > ressources > gestion des icônes
Astuce : En faisant un clic sur l'icône permettant de changer une icône de langue en maintenant la touche "alt" enfoncée, vous supprimez l'icône. Sur le portail Atomic ne sont proposées que les langues qui ont une icône. Cela permet de ne proposer vorte portail qu'en Français et Anglais, par exemple, tout en utilisant les ressources et composants génériques !
Powered by KENTIKA Atomic - © Kentika 2025 tous droits réservés - Mentions légales