 +33 4 78 17 21 16
+33 4 78 17 21 16-


- Accueil
- |
-
 L'information à 360°
L'information à 360°
- |
- Solutions
- |
- Services
- |
- Clients
- |
- Société
- |
- Actualités
6 La navigation dans le manuel de Kentika est réservée aux utilisateurs identifiés
Exporter, paramétrer et exécuter
Appartenance & droits
Exporter des données

Interopérabilité
Kentika propose de nombreuses possibilités permettant d'assurer une interopérabilité entre la base documentaire et des applications métiers installées dans l'entreprise ou des bases externes à l'entreprise. En savoir plus...
Kentika permet également de réaliser des exports de données ponctuels ou réguliers.
Déontologie
Kentika respecte complètement les règles de réversibilité relatives aux données de chaque site utilisateur. Ainsi, à tout moment, un gestionnaire peut réaliser un export de tout ou partie de son fonds, de tout ou partie des rubriques qui le décrivent.
La solution Kentika fait aujourd'hui figure d'exception dans l'application à la lettre de ces règles de déontologie.
Exporter : depuis le navigateur
A l'instar de la centrale d'importation qui centralise les options d'import automatisées, l'option "Exporter liste" propose tous les formats pré-définis. Lors de la création d'un fichier d'export depuis le navigateur, seuls les enregistrements affichés (ou sélectionnés si une une sélection préalable est réalisée) y sont intégrés L'ordre de tri courant est respecté.
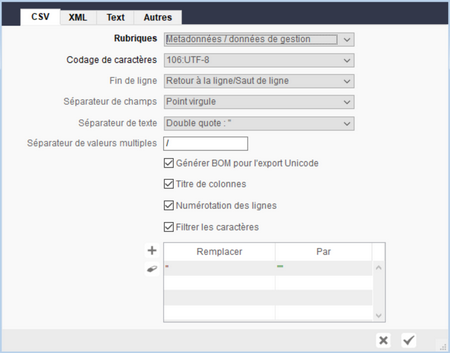
Options d'export
CSV (Comma Separated Values)
CSV, est un format texte ouvert représentant des données sous forme de valeurs séparées par des virgules. Cependant, il n'y a pas de normalisation de ce format et il faut plus le voir comme un "principe" qu'un format universel. Il présente cependant l'avantage d'être simple (une ligne par enregistrement, une colonne par champ) et de pouvoir être traité par nombre de logiciels (ex : tableurs). Cependant, comme ils ne traitent pas tous tous les cas, il convient de réaliser plusieurs tentatives avant d'obtenir un fichier qui sera exploitable correctement, que ce soit au niveau du codage que des délimiteurs.
Rubriques
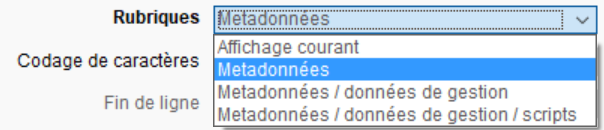
- Affichage courant : les colonnes sélectionnées dans l'explorateur de données.
- Métadonnées : toutes les rubriques définies en structure.
- Métadonnées / données de gestion : idem ci-dessus, données de gestion en plus.
- Métadonnées / données de gestion / scripts : idem ci-dessus, les rubriques script en plus.
Les valeurs sont exportées sans tenir compte de la langue choisie par l'utilisateur. Seules les rubriques auxquelles l'utilisateur a droit sont prises en compte.
Codage de caractère
Par défaut, c'est UTF8 qui est proposé. de nombreuses autres options de codage de caractères sont également disponibles.
Fin de ligne

CR/LF ; CR ; LF ou Autre : dans ce dernier cas, indiquer dans la zone située à droite les caractères délimitant chaque enregistrement.
Séparateur de champs

Si autre : le préciser dans la zone située à droite.
Séparateur de texte
Permet d'encadrer chaque valeur. Si vous exportez des textes contenant des retours à la ligne (ex : le champ "commentaire"), il est important qu'un séparateur soit fixé afin d'éviter que le retour à la ligne ne soit interprété comme un séparateur de fiches.
Séparateur de valeurs multiples
Le format csv ne prévoit pas ce cas. Il convient cependant de séparer les rubriques multivaluées, par exemple : les descripteurs, par un caractère qui ne figurerait pas dans les valeurs possibles.
Générer BOM pour l'export Unicode
Ce sont des caractères ajoutés en début du fichier pour indiquer au logiciel qui aura à l'exploiter que le fichier est en Unicode.
En général, les logiciels ne disposent pas de moyen certain de déterminer le codage d'un fichier. Aussi, il est souvent recommandé de générer le BOM (byte order mark).
Titre des colonnes
Insère, avant là première ligne, une ligne avec le nom des rubriques exportées.
Numérotation des lignes
Insère une première colonne avec un numéro séquentiel. Ceci peut être utile pour contrôler le résultat (par exemple : que les délimiteurs soient bien réglés).
Filtrer les caractères
Les champs en format libre peuvent comporter des caractères qui peuvent perturber le logiciel qui va interpréter le fichier produit, surtout s'ils sont issus de copier/coller depuis une source externe.
XML (Extensible Markup Language)
Le format XML est utilisé pour des échanges entre logiciels.
Rubriques
Idem CSV (ci-dessus).
Générer les tags

Pour un fichier facile à interpréter, il est conseillé d'utiliser les libellés des rubriques.
Inclure la zone de contenu en CDATA (Computer data)
Cette option permet d'intégrer la zone de contenu au xml produit.
Lors de la création de la zone de contenu, si des copier/coller ont été utilisés, il est possible qu'aient été collés des caractères invisibles qui peuvent perturber l'export.
Filtrer les caractères
Idem CSV (ci-dessus).
Text (ou texte avec étiquettes)
Chaque enregistrement est séparé par un double retour à la ligne. Chaque rubrique est séparée de la suivante par un retour. En début de ligne figure une étiquette. Les rubriques non renseignées ne sont pas exportées. Si une rubrique comporte un retour à la ligne, un retrait peut être généré.
TITRE: Le baron perche
DATEDEPARUTION: 2012
REFERENCE: Gallimard
AUTEURS: Calvino / BERTRAND, Juliette / Rueff
THEME: Culture
NBRENDEPAGE: 400 p.
COTE: ITA123
DATEDEPARUTION: 2012
REFERENCE: Gallimard
AUTEURS: Calvino / BERTRAND, Juliette / Rueff
THEME: Culture
NBRENDEPAGE: 400 p.
COTE: ITA123
Ce type format est le plus couramment rencontré dans les échanges entre fonds documentaires car il présente l'avantage d'être simple à lire et à traiter en importation de données.
Autres formats
Dublin core : le format est imposé, le contenu à faire figurer pour chaque champ est librement paramétrable.
RIS (Research Information System) : le format est imposé, le contenu à faire figurer pour chaque champ est paramétrable. Le principe est identique au Dublin Core, il y a une mise en correspondance des types de document avec la liste imposée des types RIS à effectuer.
Marc : le fichier produit est au format ISO2709. Les rubriques exportées sont définies au niveau de la structure : il suffit, pour chaque rubrique à exporter d'indiquer sa zone / sous-zone.

Fichier : créé une page html d'index et place dans des répertoires les fichiers des enregistrements sélectionnés.
La page permettant de réaliser l'index est calculée à partir d'une ressources web intitulée File://A_Index.htm. Elle peut donc être personnalisée.
NB : lors de chaque génération d'un tel fichier/dossier d'export, l'éventuel précédent est remplacé.
Le nombre de documents ainsi exportés peut être limité par le paramètre W_NX (voir : préférences/paramètres de connexion/Atomic special).
html : propose de créer un fichier html en utilisant un modèle créé sous la forme d'une ressource web.
NB : pour qu'une ressource web soit proposée ici il faut que son nom soit construit de la manière suivante : "File://Template_03" suivi du nom de la liste et se terminant par ".htm", exemple : "File://Template_03Liste_de_documents_simple.htm".
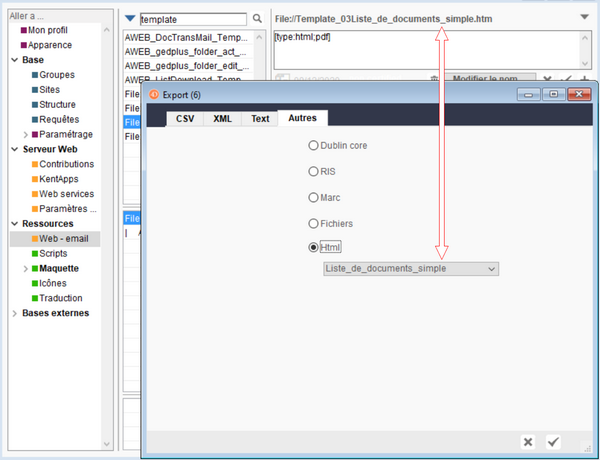
Le fonctionnement de cet export est analogue à celui proposé (en version 4) sur le portail.
Autres options disponibles
Il existe dans Kentika d'autres possibilités d'export :
- exporter le thesaurus, sous différents formats
- au format docx en utilisant une maquette traitement de text
- au format pdf avec une page de garde et les fichiers pdf assemblés
- au format interne Kentika pour réaliser des échanges avec d'autres bases Kentika
- via l'API KAAT
- au travers des options proposées sur le portail
Powered by KENTIKA Atomic - © Kentika 2025 tous droits réservés - Mentions légales