 +33 4 78 17 21 16
+33 4 78 17 21 16-


- Accueil
- |
-
 L'information à 360°
L'information à 360°
- |
- Solutions
- |
- Services
- |
- Clients
- |
- Société
- |
- Actualités
6 La navigation dans le manuel de Kentika est réservée aux utilisateurs identifiés
Import de données textuelles : onglet champs
Appartenance & droits
Importer des données textuelles : onglet "Champs"
Préambule
Lors de l'importation de données, après avoir indiqué le codage du fichier, et la structure des données, ce dialogue permet d'indiquer quels champs correspondent à quelles données du fichier et quels sont les traitements complémentaires à leur faire subir.
Fonctionnement
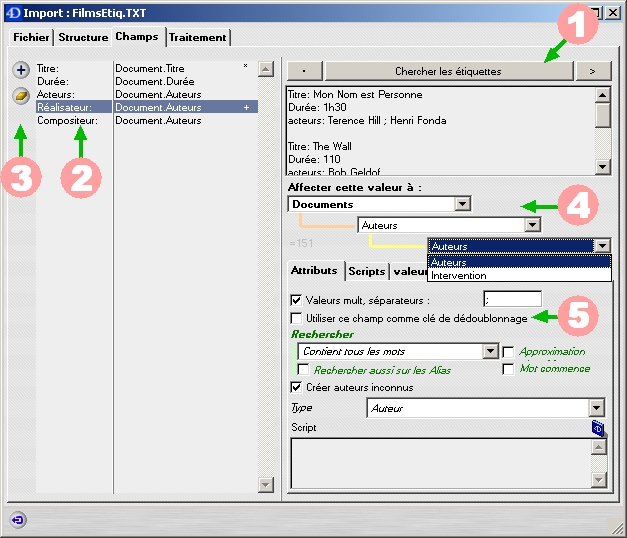 Analyse et traitements des différents champs
Analyse et traitements des différents champs
Identification des étiquettes
1 Assistant d'analyse du fichier
La recherche d'étiquettes dépend de la structure du fichier.
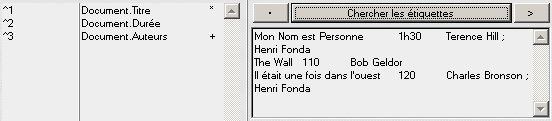
Cette assistant recherche des étiquettes dans la portion du fichier lue dans la zone de texte et limitée à 32000 caractères.
Bouton à droite : > permet de lire la suite du fichier ; le bouton à gauche : . permet de revenir au début du fichier.
Texte avec séparateurs
Dans le cas d'une structure de texte avec séparateurs, l'application compte le nombre de séparateurs par fiches et détermine ainsi le nombre de champs (égal au nombre de séparateurs trouvés plus un). Ces derniers sont repérés dans le tableau de gauche par les symboles : ^1 ; ^2 ... (^2 signifie : la deuxième valeur).
Texte avec étiquettes
L'assistant permet d'identifier des séquences dans le texte. En général, une étiquette suit le séparateur de rubrique et est séparée de la valeur par un signe de ponctuation ( : en général). Pour repérer de telles séquences, on indique le séparateur de rubrique suivi du symbole @ et du signe marquant la fin de l'étiquette. Si l'étiquette a une longueur fixe (exemple : 3 caractères) on indiquera comme séquence le séparateur de rubrique suivi d'un nombre de # égal au nombre de caractères de chaque étiquette (exemple : ^p###).
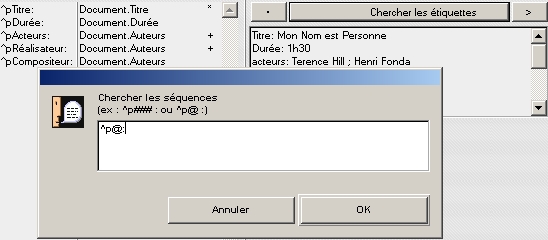
Recherche des séquences : retour à la ligne puis un nombre quelconque de caractères avant ls signe :
Il arriva parfois que des étiquettes occasionnelles ne se trouvent pas dans le début du fichier, il faut alors utiliser le bouton > pour les chercher dans la suite. Elles seront ajoutées au tableau des étiquettes déjà identifiées.

Confirmation des étiquettes trouvées avant alimentation du tableau
Longueur fixe
La démarche pour les enregistrements de longueur fixe est différente. Elle consiste à sélectionner successivement les parties de texte correspondant à un champ puis à cliquer sur le bouton +.
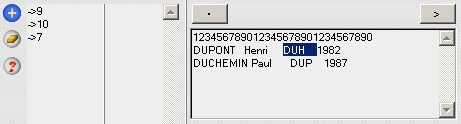
La longueur de chaque champ apparaît dans la colonne de gauche avec le signe -> devant.
NB : dans l'exemple ci-dessus, il y a un retour à la ligne entre les enregistrements. Il faudra ajouter un champ à ignorer de longueur 1 en fin de tableau.
Modification des étiquettes
2 Double clic sur l'intitulé pour modifier une étiquette (texte avec étiquette)
Dans le cas d'un texte en longueur fixe, le logiciel propose de modifier la longueur de la chaîne identifiée.
Ajout, suppression
3 Insérer, effacer un champ
Ajout : la ligne sera ajoutée avant la ligne sélectionnée. Pour ajouter une ligne en fin de tableau, il faut qu'aucune ligne ne soit sélectionnée.
Suppression : si une ligne est sélectionnée et qu'une rubrique est déjà affectée, l'étiquette est conservée mais l'affectation est effacée. Si aucune rubrique n'est affectée, l'étiquette est effacée. Si aucune ligne n'est sélectionnée et qu'il existe des étiquettes non affectées, ces étiquettes sont effacées. Si toutes les étiquettes sont affectées, elles seront toutes supprimées.
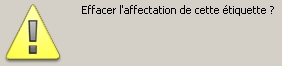
Confirmation de l'opération de suppression
Rubrique d'affectation
4 Choix de la table, de la rubrique, voire de la sous-rubrique
Par défaut, c'est la table d'import qui est proposée. Les cas d'import avec alimentation secondaire d'une table autre que la table d'import sont décrits ci-après. Les rubriques proposées sont celles de la table d'import. Dans le cas de rubriques groupées, la rubrique de tête est proposée dans le deuxième menu, les autres rubriques sont proposées dans le troisième menu.
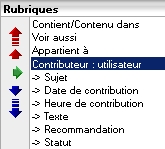
Zone de groupe définie en structure
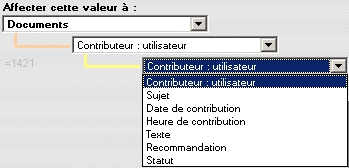
et proposée lors de l'import de données
Attention : dans le cas d'un import dans un groupe (comme illustré ci-dessus), il faut toujours que soit alimentée la rubrique de tête en premier (utilisateur dans l'exemple ci-dessus). Si cette information est située après un des champs suivants (exemple : Sujet), il faut placer le contenu du champ dans une variable puis alimenter le sujet à l'aide du contenu de cette variable.
Affecter le contenu à une variable
Dans certains cas, l'import direct de champ à champ n'est pas possible. Aussi, on peut être amené à conserver temporairement le contenu dans une variable puis exploiter cette dernière dans un script (exemple : script après création de fiche définie dans l'onglet "Structure").
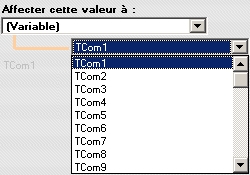
Conserver le contenu dans une variable
Alimentation de rubriques de tables liées
Les informations figurant dans le fichier importé peuvent concerner des rubriques d'une table liée à la table dans laquelle sont créés les enregistrements principaux.
Exemple
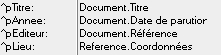
Dans le fichier suivant, le champ "Lieu" concerne l'éditeur :
Titre: La maison sur le lac
Annee: 1984
Editeur: Litterateur
Lieu: Paris
Titre: Un singe en été
Annee: 1954
Editeur: Armateur
Lieu: Reims
et doit alimenter la rubrique "coordonnées" de la table référence
en simulation de traitement, le résultat est présenté ainsi :

Traitement d'un champ
5 Attributs, scripts, valeurs
- Attributs : permet de définir des compléments propres à chacun des champs. Les attributs possibles dépendent de la nature de la rubrique dans laquelle l'information lue dans le fichier est importée.
- Scripts : permet d'intervenir sur le contenu du champ.
- Valeurs : permet de visualiser les valeurs trouvées dans le fichier.
Attributs communs à toutes les natures de rubrique

Valeurs multiples : si un champ d'un fichier importé comporte plusieurs valeurs et qu'il alimente une rubrique multi-valuée, le champ peut être découpé autour du séparateur.
Exemple
Titre: Mon Nom est Personne
Durée: 90
Acteurs: Terence Hill ; Henri Fonda
Le champ acteurs comporte deux valeurs séparées par le signe ;

Clé de dédoublonnage : il se peut que des enregistrements que l'on s'apprête à importer existent déjà dans la base de données. Dans ce cas, il faut éviter de créer des enregistrements en double. Pour identifier les doublons, on spécifie des champs dont les valeurs serviront de critère de recherche. La manière de traiter des doublons se règle sur l'cran suivant "Traitement". La recherche de doublons ne tient compte que des champs qui comportent une valeur et, si plusieurs champs ont été marqués comme clé de dédoublonnage, le critère de combinaison est le ET. Si lors du doublonnage plus d'un enregistrement sont trouvés comme correspondant à celui qui est importé, ce dernier est ignoré.
Attribut lors d'import d'un champ dans une rubrique de type "code"
Le logiciel tente d'identifier à quelle valeur possible pour la rubrique correspond la valeur trouvée dans le fichier en recherchant sur le code puis sur l'intitulé. Si une valeur n'existe pas, on peut décider soit de créér un nouveau code / valeur pour la rubrique, soit d'affecter la valeur inconnue a une autre rubrique.
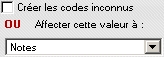
Traitement particulier si la valeur ne correspond à aucune valeur connue
NB : si le fichier importé utilise une codification des informations différente de celle de votre application, vous pouvez, soit appliquer un filtre afin de changer une valeur par une autre, soit effectuer des transformations sur la valeur par script.
Attribut lors de l'import d'un champ dans une rubrique de type "thesaurus"
Une telle rubrique est en fait un lien entre deux enregistrements. Une valeur n'est acceptée que si elle correspond bien à un descripteur du thesaurus et, éventuellement, à la branche du thesaurus spécifiée pour la rubrique de destination. Les écritures peuvent varier pour un même descripteur entre la valeur que l'on importe et celle présente dans votre base de données. Aussi, le logiciel offre la possibilité de fixer le mode de recherche ("Est égal à l'expression" dans l'exemple ci-dessous). Attention à ne pas mettre un réglage trop "lache" (exemple : contient un des mots) sinon un descripteur pourrait être pris pour un autre au moment de l'import.
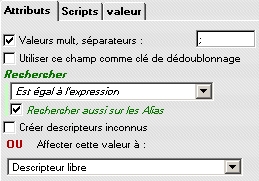
Règles de recherche et de traitement si le descripteur n'est pas trouvé dans le thesaurus
Si aucun descripteur ne correspond à la valeur importée, l'option "Créer descripteurs inconnus" permet de forcer la création automatique d'un descripteur dans votre base de données. Si vous ne souhaitez pas activer cette possibilité (en effet, des imports intempestifs peuvent vite polluer votre thesaurus), vous pouvez décider d'affecter les valeurs inconnues à une rubrique alternative (un rubrique "Descripteur libre" de nature "format libre" dans l'exemple ci-dessus).
Si un descripteur est créé lors de l'import de données, il est automatiquement rattaché à "Candidat". Si une branche de thésaurus est spécifiée pour la rubrique de destination, le candidat-descripteur est également automatiquement rattaché à cette branche.
Attribut lors d'import d'un champ dans une rubrique de type "lien"
Une telle rubrique est un lien entre deux enregistrements de la base de données. Son comportement est très comparable à ce qui est décrit ci-dessus pour les rubriques de type thesaurus.
Lors de la création d'un enregistrement dans une table liée, le type doit être fixé et il est possible de provoquer l'alimentation de rubriques de la fiche liée par programmation (la rubrique commentaire comportera "Auteur créé lors de l'import de données").
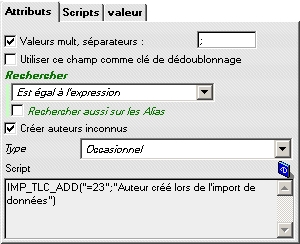
Lors du traitement, un tel paramétrage provoquera la création d'un enregistrement auteur comme suit :

La recherche de la valeur dans la table s'ffectue par défaut sur le titre pour lien sur la table document, le nom pour un lien sur la table auteur ou référence et l'identifiant pour un lien sur la table des personnes.
Il est possible de modifier ce comportement par défaut en affectant un numéro de rubrique (précédé du signe=) à une fiche paramètre dont le code doit être : S= et suivi du numéro de table sur deux caractères.
Exemple : si le paramètre "S=03" vaut "=71", la recherche s'effectuera sur la cote du document et non sur le titre.
Script
La création d'un script fait appel à des compétences en programmation. Une erreur de syntaxe provoquera à coup sûr un arrêt de l'application. Mettez au point les scripts sur une base de test avant de les mettre en exploitation.
Le résultat de ce qui est extrait est contenu dans la variable "TCom". Si une transformation doit être effectuée, le contenu doit également être renvoyé dans cette même variable.
Exemple
TCom:=Remplacer chaine(TCom;"bonjour";"hello")
IMP_TLC_ADD (Code rubrique ; valeur)
Permet de provoquer l'ajout d'une ligne dans le tableau des valeurs importées pour un enregistrement donné.
Le code de la rubrique doit être exprimé sous la forme : = suivi du numéro de rubrique ; la valeur doit être obligatoirement exprimée en alphanumérique.
Exemple
Si la durée du film est supérieure ou égale à 120 minutes, la rubrique commentaire de la fiche document aura pour valeur "Ce film dure plus de 2 heures".
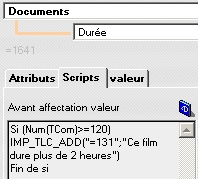
Le résultat du traitement en mode simulation se présentera ainsi :

NB : le script avant affectation permet d'intervenir sur le contenu qui sera affecté à la rubrique, le script après affectation permet d'intervenir après (exemple : cas d'alimentation de zones de groupes complexes).
Trouver les valeurs
Particulièrement utile en phase de mise au point, cette fonction permet d'explorer le contenu du fichier afin de vérifier les valeurs qui y sont présentes. Le nombre de valeurs (découpées en cas de valeurs multiples) peut être augmenté pour avoir un échantillonnage large. Dans la liste à gauche sont présentées les valeurs trouvées. En cliquant sur une valeur, le script avant affectation est appliqué et le résultat de son exécution est présentée dans la zone à droite.
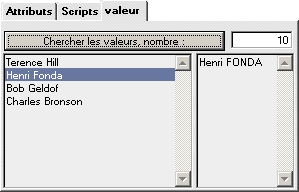
Valeurs trouvées dans le fichier à importer
Le script appliqué ici permettant d'avoir le nom de famille en majuscule est :
Ex:=Position(" ";TCom)
Si (Ex>0)
TCom:=Sous chaine(TCom;1;Ex)+Majusc(Sous chaine(TCom;Ex+1))
Fin de si
Traitement
Les champs étant maintenant définis, il reste à vérifier que le résultat semble correct avant de procéder à l'import des données ou bien à l'enregistrement du filtre d'import. Pour ce faire, cliquer sur l'onglet "Traitement".
Powered by KENTIKA Atomic - © Kentika 2025 tous droits réservés - Mentions légales