 +33 4 78 17 21 16
+33 4 78 17 21 16-


- Accueil
- |
-
 L'information à 360°
L'information à 360°
- |
- Solutions
- |
- Services
- |
- Clients
- |
- Société
- |
- Actualités
6 La navigation dans le manuel de Kentika est réservée aux utilisateurs identifiés
Connecteur http : analyser le résultat d'une page
Appartenance & droits
Connecteur HTTP : analyse du résultat
Préambule
La réalisation d'un connecteur d'accès à une base externe de type HTTP se décompose en deux étapes : construire la requête puis l'analyser.
Cette deuxième étape nécessite des bases en programmation sur la manipulation de chaînes de caractères avec le langage de 4D. Rappelons ici les 3 principales fonctions que vous pouvez être amené à utiliser : Position ; Sous chaîne ; Remplacer chaîne
Il se peut que vous découvriez dans les exemples de connecteurs une programmation plus sophistiquée mais ces trois fonctions représentent 80% des scripts.
L'analyse du résultat s'effectue directement sur une page html qui a été téléchargée lors du test de la construction de la requête. Donc, tant que la requête n'a pas été exécutée correctement, cette deuxième étape ne peut être entreprise.
Avant de commencer cette analyse, il est conseillé de vous assurez que lorsque vous demandez à ouvrir une page dans votre navigateur en cliquant sur le bouton situé en bas à droite du résultat de l'écran précédent, l'affichage est comparable à ce que vous obtenez lorsque vous posez une question à l'aide de votre navigateur.
Dialogue d'analyse du résultat
La page étant acquise depuis le site, il faut travailler par approches successives jusqu'à ce que le résultat apparaisse sous forme d'enregistrements correctements découpés.

Analyse du résultat : de la page aux enregistrements
Repérage visuel
Une première analyse visuelle de la page nous informe des informations que nous allons vouloir extraire du résultat.

Informations à extraire de la page
Analyse du code source en html
L'analyse s'effectuant à partir du source html du résultat, de cette analyse visuelle nous allons tenter de comprendre comment les informations que nous voyons sont codées. A l'aide de la fonction permettant de visualiser le fichier source du navigateur, nous allons repérer le début du premier item de la liste.
Le principe de l'analyse consiste à baliser le texte avec des valeurs qui seront ensuite utilisées comme des marqueurs de début d'enregistrement et de début de champ. Lors de l'exécution de l'analyse d'une page, après avoir placé les balises, le logiciel relit ce qui figure entre les balises et exécute les scripts eventuels. Ensuite, il affecte ce qui a été trouvé aux champs correspondant aux intitulés des balises.
Source initial
<div><h3><a class=yschttl href=" http://fr.wrs.yahoo.com/_ylt=A1f4cfsxDIJHezIACEJjAQx.; _ylu=X3oDMTExcXNkdQ--/SIG=124reg19v/EXP=1199791537/* *http%3A//fr.wikipedia.org/wiki/Mastaba_de_Khentika" >Mastaba de <b>Khentika </b> - Wikipédia </a></h3>
</div>
<div class=abstr> Le mastaba de <b>Khentika </b> est l'un des seuls témoignages quasiment intacts de l' ... Gouverneur de l'oasis de Dakhla, <b>Khentika </b> occupe une fonction importante de ... </div><div class=active>Liens directs : <a href="http://fr.wrs.yahoo.com/_ylt=A1f4cfsxDIJHezIACUJjAQx./SIG=132a4luml/EXP=1199791537/* *http%3A//fr.wikipedia.org/wiki/Cat%25C3%25A9gorie%3AIndex_%25C3%25A9gyptologique">Index égyptologique</a> - <a href="http://fr.wrs.yahoo.com/_ylt=A1f4cfsxDIJHezIACkJjAQx./SIG=13ebcqfmb/EXP=1199791537/* *http%3A//fr.wikipedia.org/wiki/Cat%25C3%25A9gorie%3 ATombeau_de_l%2527%25C3%2589gypte_antique">Tombeau de l'Égypte antique</a> </div> <span class=url> <b>fr.wikipedia.org </b>/wiki/Mastaba_de_ <wbr /><b>Khentika </b></span>
- <em>16k</em>
- <a href="http://fr.wrs.yahoo.com/_ylt=A1f4cfsxDIJHezIAC0JjAQx./SIG=15ljdf37d/EXP=1199791537/* *http%3A//72.30.186.56/search/cache%3Fei=UTF-8%26p=Khentika%26fr=moz2%26u=fr.wikipedia.org/wiki/Mastaba_de_Khentika% 26w=khentika%26d=KdGkb7XiQFJo%26icp=1%26.intl=fr">En cache</a>
</li>
La balise <a class=yschttl href=" figure en début de chaque item. De plus, ce qui suit cette balise contient le titre. Elle va donc être utilisée comme balise de début d'enregistrement : $$KV_Record_Begin et comme balise de champ titre : $$KV_Titre
Dans l'exemple ci-dessus, après remplacement des balises et exécution des scripts, le contenu de la page est transformé en :
Source balisé
$$KV_Record_Begin
$$KV_Titre Mastaba de Khentika - Wikip²©dia
$$KV_Commentaire : Le mastaba de Khentika est l'un des seuls t²©moignages quasiment intacts de l' ... Gouverneur de l'oasis de Dakhla, Khentika occupe une fonction importante de...
$$KV_URL : fr.wikipedia.org/wiki/Mastaba_de_Khentika
Il ne reste plus alors qu'à reprendre le contenu du texte figurant entre les balises, à appliquer le filtrage des caractères pour obtenir ceci :
Enregistrement extrait
<Titre>Mastaba de Khentika - Wikipédia</Titre>
<Commentaire>Le mastaba de Khentika est l'un des seuls témoignages quasiment intacts de l'... Gouverneur de l'oasis de Dakhla, Khentika occupe une fonction importante de... </Commentaire>
<URL>fr.wikipedia.org/wiki/Mastaba_de_Khentika</URL>
Ordre des opérations
Lorsque le connecteur a téléchargé la page, il effectue les opérations dans l'ordre décrit ci-après.
Attention : cet ordre a de l'importance car si l'on supprime une chaîne de caractère que l'on veut ensuite utiliser comme balise, cette dernière ne sera pas reconnue.
La page est lue à partir de la balise "<body" (si elle est présente, depuis le début sinon). Les commentaires et javascripts sont supprimés du texte analysé.
A Supprime les chaînes à supprimer
B Remplacer les chaînes à remplacer
C Elimine les balises (avec un traitement particulier pour les form, select et script)
D Exécute les scripts
E Constitue les enregistrements et filtre les caractères
Les étapes A à D (qui font passer le texte de l'état source html du pavé 7 à l'état contenu filtré du pavé 8 ) ont pour objectif de préparer l'opération finale qui consiste à extraire le texte restant entre les balises et à constituer les enregistrements (pavé 6 ).
Chaînes à supprimer
1 Les chaînes de caractères à supprimer doivent être séparées par des retour à la ligne
Pour supprimer les signes tabulation, saisissez : ^t
Chaînes à remplacer
2 A exprimer sous la forme : (ancienne valeur).=.(nouvelle valeur)
Cette étape est l'étape déterminante dans l'analyse de la page. En effet, elle consiste à placer des balises afin que soient identifiés les enregistrements.
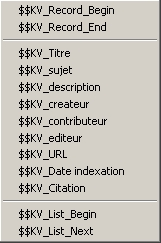
$$KV_Record_Begin : balise de début d'enregistrement
$$KV_Record_End : balise de fin d'enregistrement. Si une telle balise n'est pas trouvée, c'est la prochaine balise de début qui fait office de fin d'enregistrement
$$KV_(nom du champ) : balise de début de champ, la valeur du champ étant l'intégralité du texte situé entre cette balise et la prochaine balise $$KV_...
NB : afin de créer une balise correspondant à un champ hors dictionnaire des champs apparents, il suffit de le saisir sous cette forme ($$KV_...), la valeur trouvée sera ajoutée à l'enregistrement (utilisable en import de données mais pas en affichage dans l'explorateur de données).
$$KV_List_Begin : balise de début de liste. Ceci est utile dans le cas où il y a des risques de confusion au niveau du début réel de la liste
$$KV_List_Next : balise marquant l'indication de page suivante. Cette balise ne fonctionne pas comme une balise de remplacement : en fait, lors de l'exécution du connecteur, le logiciel recherche le premier lien (<a href...) situé avant cette balise et l'URL trouvée est considérée comme étant la page suivante. Le logiciel l'invoque jusqu'il ne trouve plus cette balise ou lorsque le nombre d'enregistrements est atteint (tel précisé en première étape).
NB : une même balise peut être placée plusieurs fois (cas où des présentations peuvent varier d'un enregistrement à l'autre).
Mode opératoire
Dans le pavé contenu filtré (8 ), sélectionnez la chaîne de caractère à remplacer puis cliquez sur le point rouge afin de sélectionner une balise dans le pop-up tel que figurant ci-dessus.
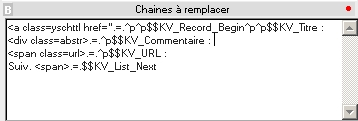
Remplacement : un par ligne
NB : pour remplacer ou ajouter un retour à la ligne, indiquez le sous la forme ^p ; l'étiquette de début ($$KV_Record_Begin) est en général commune à celle marquant le début d'un champ (Titre dans l'exemple ci-dessus).
Etiquettes html à supprimer
3 Exprimées sans les signes < et > ; une valeur par ligne
En indiquant une étiquette, la balise de fin sera également supprimée.
Exemple : si vous indiquez div, les séquences suivantes seront supprimées :
<div>
<div class="a>
</div>
par contre, ce qui figure entre <div> et </div> serait conservé.
Cas spéciaux : select : form et script
Dans le cas de ces trois étiquettes, tout ce qui est situé entre la balise de début (exemple : <script ...> ) et la balise de fin (exemple : </script) sera supprimé.
Scripts
4 Appliqué à une balise sur le contenu... jusqu'à la prochaine balise
Lors de l'écriture d'un tel script, le contenu de ce qui a été trouvé est placé dans la variable $0, le résultat doit être retourné dans cette même variable.
Dans l'exemple ci-dessus, la zone de titre a été identifié, de même que la zone commentaire. Cependant, seule la partie située entre le signe > et le signe < doit être conservée :
$$KV_Record_Begin
$$KV_Titre : http://fr.wikipedia.org/wiki/Mastaba_de_Khentika" > Mastaba de Khentika - Wikip²©dia </a></h3> </div>
$$KV_Commentaire
Le script à appliquer au titre est :
Ex:=Position(">";$0)
$0:=Sous chaine($0;Ex+1)
Ex:=Position("<";$0)
$0:=Sous chaine($0;1;Ex-1)
Pour créer un tel script, cliquez sur le bouton + puis sélectionnez l'étiquette à l'aide du pop-up apparaissant en cliquant sur le point bleu.
NB : ce pop-up est un assistant mais il est possible également de créer un script pour une balise qui ne correspondrait pas à un champ du dictionnaire des champs apparents. Ceci est à réserver à des exploitations avancées des connecteurs avec récupération de champs hors dictionnaire.
Filtrage des caractères
5 Si disponible, sélectionnez le jeu de caractères des informations reçues.
Il se peut qu'aucun des filtres proposés ne donnent des résultats satisfaisants. Dans ce cas, vous aurez à créer votre propre filtre en utilisant la fonction de remplacement (2 ).
Appliquer les règles : "Nettoyer maintenant"
6 Effectuer les transformations et contrôler le résultat
En cliquant sur ce bouton, vous verrez apparaître dans le pavé "contenu filtré" le résultat des transformations et dans "enregistrements identifiés" la liste des enregistrements trouvés dans la première page.
Attention : ce test ne s'applique qu'à la page courante. La récupération des pages suivantes ne peut être vérifiée qu'en utilisant le connecteur dans l'explorateur de données.
Affichage du contenu html de la page
7 Code html... visualisation de premier niveau
Il est conseillé d'ouvrir également le source dans un navigateur qui propose en général plus d'options pour une bonne lisibilité du code (indentation, couleur, style... en fonction des balises) et identifier ainsi les séquences que l'on va pouvoir utiliser pour découper le résultat.
Contenu filtré
8 Permet de contrôler l'état des transformations juste avant le découpage en enregistrements
Enregistrements identifiés
9 Liste des enregistrements trouvés dans la première page
En sélectionnant un enregistrement de cette liste, son contenu apparaît dans la zone située à droite. A priori, le nombre d'enregistrements présents dans cette liste doit correspondre à celui que l'on obtient avec un navigateur. Il se peut cependant que les derniers enregistrements soient manquants. En effet, en mode "analyse", le connecteur travaille sur une zone de texte de 32 000 caractères (alors qu'il travaille sur l'intégralité du flux lors de l'exécution en situation réelle). Si la page reçue est très volumineuse, les derniers enregistrements seront peut être manquants.
Il convient ici de bien vérifier qu'il n'y a pas de manque intermédiaire. En effet, il se peut qu'une balise que l'on utilise pour identifier les débuts des enregistrements soient légèrement différente pour certains enregistrements (exemple : si l'on utilise une balise de style et si tous les enregistrements ne sont pas présentés de la même manière) dans ce cas, des enregistrements ne seraient pas identifiés.
Contenu d'un enregistrement
10 Ultime étape de la vérification : contrôle du contenu
L'ajustement des réglages (étapes 1 à 6 ) doit être repété jusqu'à ce le résultat soit correct.
Lien propagé
11 Accès à une deuxième page de réglage
Certains sites proposent une liste avec quelques informations et lorsque l'on active un lien, affichent des informations détaillées.
Le lien vers cette deuxième page doit être repéré par la balise "$$KV_URL_Level2"
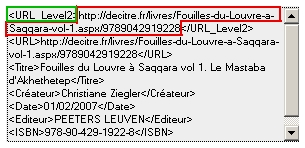
URL de niveau 2 identifiée
Cette deuxième série de pages (une par enregistrement) doit être alors analysée en suivant le même principe que la liste principale.
Powered by KENTIKA Atomic - © Kentika 2025 tous droits réservés - Mentions légales