 +33 4 78 17 21 16
+33 4 78 17 21 16-


- Accueil
- |
-
 L'information à 360°
L'information à 360°
- |
- Solutions
- |
- Services
- |
- Clients
- |
- Société
- |
- Actualités
6 La navigation dans le manuel de Kentika est réservée aux utilisateurs identifiés
Import de données textuelles : onglet Structure
Appartenance & droits
Importer des données textuelles : onglet "Structure"
Préambule
Lors de l'importation de données, après avoir indiqué le codage du fichier, ce dialogue permet d'indiquer comment sont structurés les enregistrements et quelle table de la base de données doit être alimentée.
Fonctionnement
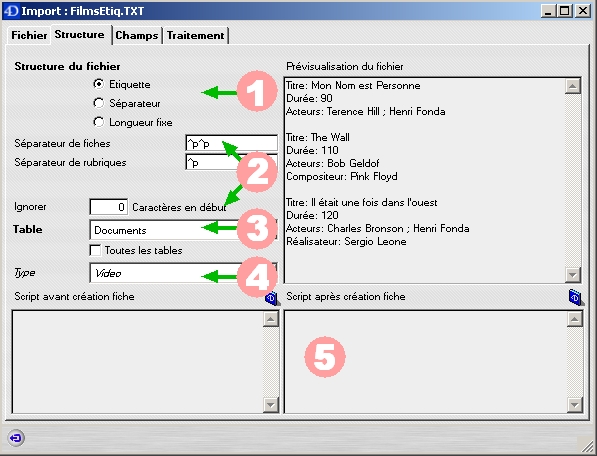
Structure du fichier ; destination des enregistrements et traitements complémentaires par script
Structure du fichier
1 Choix entre trois formats
Les informations complémentaires nécessaires au découpage dépendent de la structure du fichier.
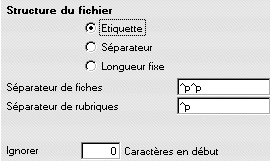
Texte avec étiquette
Cette structure est particulièrement adaptée au contexte documentaire où le nombre d'informations peut varier d'une enregistrement à l'autre et où les champs peuvent avoir une longueur importante. En général, le séparateur entre fiches sera un double retour (soit, une ligne blanche lors de la lecture visuelle du fichier) et le séparateur entre rubriques sera un simple retour (comme dans l'exemple affiché dans le dialogue ci-dessus).
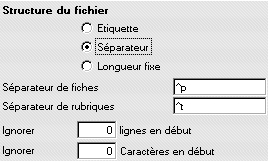
Texte avec séparateur
Cette structure est une des plus couramment rencontrée. En règle générale, le séparateur de fiche est un retour à la ligne (^p) et le séparateur de rubrique une tabulation (^t) ou un signe ;.
Si le fichier comporte des guillemets (ou un autre signe) autour des valeurs, il faut l'indiquer dans le séparateur de rubriques.
Exemple
Si les informations sont structurées comme ceci :
"DUPONT";"Albert";"DUA";1982
"DUCHEMIN";"Henri";"DUH";1987
Il faut indiquer dans la zone séparateur de rubrique :
";"
NB : avec cette structure, il n'est pas possible d'avoir des retours au sein des rubriques (sauf, éventuellement, sous forme codés). Cette structure n'est donc pas idéale pour des données documentaires. Par contre, elle sera fréquemment rencontrée lors d'import de données issues d'une base de données, pour alimenter la table des personnes par exemple.
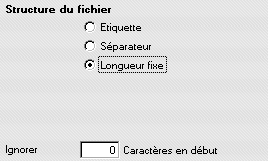
Longueur fixe
Cette structure est de moins en moins courante et correspond à des export réalisées à partir d'applications de gestion de fichiers. Dans ce type de structure, chaque valeur de rubrique occupe le même nombre de caractères (et est généralement complétée par des espaces).
Séparateurs
2 Entre fiches / entre rubriques
En complément, il possible de demander à ignorer des lignes et / ou des caractères en début de fichier. Dans le cas d'un fichier en tab/tab/retour (séparateur entre fiche est un retour : ^p et le séparateur entre fiches est une tabulation : ^t), il arrive que la première ligne corresponde à l'intitulé des colonnes. Dans ce cas, une ligne devra être ignorée et l'import ne commencera qu'à partir de la deuxième ligne.
Table
3 Destination des enregistrements importés
Par défaut, sont proposées les tables de la base de données, hormis les tables dites "techniques".
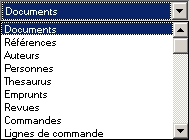
Choix de la table dans laquelle importer les données
Il est cependant possible d'importer des données dans toutes les tables (en cochant préalablement l'option "Toutes les tables"), à condition de bien connaître la structure interne des informations. Ceci sera donc réservé à des cas exceptionnels.
Type
4 Pour les tables : Documents, références, auteurs, personnes et revues
Les autres tables n'étant pas déclinées en types, cette option n'est pas proposée.
Scripts avant et après création de la fiche
5 Traitements complémentaires éventuels
Script avant création de la fiche : est exécuté avant que la fiche ne soit chargée en mémoire. Ce script n'est pas exécuté lorsque l'import provoque la mise à jour d'un enregistrement existant.
Script après création de la fiche : est exécuté à l'enregistrement de la fiche.
Si le script après création de la fiche contient des alimentations de rubriques à l'aide de la fonction Field_Set et que des opérations complémentaires doivent être exécutées, il faut placer un ligne de séparation entre les deux blocs comportant "End_Field_Set"
Exemple : si le fichier importé comporte un chemin d'accès à un fichier sur le disque et que ce dernier doit être archivé, il faut écrire un script après création dans lequel sera relu le chemin d'accès et le fichier sera archivé (AR_Archive_File).
Champs
La structure et la destination étant identifiées, il reste à alimenter les champs (ou rubriques) de l'enregistrement qui reçoit les informations.
Powered by KENTIKA Atomic - © Kentika 2025 tous droits réservés - Mentions légales