 +33 4 78 17 21 16
+33 4 78 17 21 16-


- Accueil
- |
-
 L'information à 360°
L'information à 360°
- |
- Solutions
- |
- Services
- |
- Clients
- |
- Société
- |
- Actualités
6 La navigation dans le manuel de Kentika est réservée aux utilisateurs identifiés
Importer des données
Appartenance & droits
Importer des données
Préambule
Alimenter sa base de données peut s'effectuer de deux manières : en saisissant une information (dans l'application ou via l'interface web) ou bien en l'important. Si une information existe déjà sous forme électronique, il est judicieux d'étudier s'il existe une solution permettant de l'importer. Vous trouverez dans le logiciel tout un inventaire de possibilités d'importation de données.
Si une donnée est enregistrée dans une base de données Kentika puis exportée en vue d'être intégrée dans une autre base Kentika, le fichier produit ne peut être lu que par Kentika. La donnée est fournie avec toute une série d'informations complémentaire permettant d'en assurer une intégration dans les meilleures conditions.
Les données que vous recevez d'une autre application doivent faire l'objet d'une analyse préalable détaillée. En effet, outre le fait que ces dernières doivent pouvoir être interprétées, il faut également leur assurer une intégration la plus "propre" possible. On peut très rapidement rendre une base de données inexploitable si l'on réalise des imports sans précautions.
Précaution : avant de procéder à un nouveau type d'import, il est fortement recommandé de travailler à la mise au point du filtre d'import dans une copie de la base puis d'exporter le filtre d'import dans votre base en exploitation lorsque celui-ci est tout à fait au point. De plus, si certains imports sont faciles à réaliser, il se peut que d'autres nécessitent de réelles compétences en programmation.
Pour accéder aux fonctions d'import, vous devez disposer dans votre application d'un script contenant l'appel à la fonction d'import de données : IMP_CHOIX .
Les étapes de l'analyse
Format des données ou comment sont structurées les informations au sein du fichier. Il existe des formats qui ont pour vocation de permettre une lecture par un oeil humain (texte tabulé, texte avec étiquettes...), d'autres qui ne sont faits que pour être relus par un logiciel (Marc 2709, XML, html...). Pour la deuxième catégorie, une première étape de conversion sera réalisée avant de pouvoir exploiter l'assistant de création de filtre.
Codage des caractères : principalement pour les caractères accentués ou les signes spéciaux. Certains formats imposent un codage (exemple : XML, Marc 2709), d'autres permettent tout type de codage. Certains cas nécesseront de déterminer une table de conversion de caractères.
Structure des informations : une séquence de caractères devra permettre d'isoler, au sein du fichier, les enregistrements puis à l'intérieur d'un enregistrement, les différents champs qui le compose.
Correspondance avec la base de données : un fichier importé va donner naissance à des enregistrements d'une table (document, auteur, référence...) ayant un type donné. Les champs trouvés dans ces enregistrements alimenteront les rubriques des nouveaux enregistrements.
Dédoublonnage : il se peut qu'un fichier comporte un enregistrement déjà présent dans la base de données. Des règles de dédoublonnage vont permettre d'identifier de tels enregistrements puis, soit mettre à jour l'enregistrement déjà présent ou bien rejeter celui trouvé dans le fichier importé.
Avancé : la correspondance champ à champ ne s'applique pas systématiquement. Dans ce cas, un script permettra d'adapter la donnée trouvée dans le fichier à ce que la base de données accepte de recevoir.
L'ensemble des paramètres qui seront ainsi déterminés pour importer un type de fichier donné sont enregistrés dans un et un seul enregistrement de la table "maquettes" (voir ci-après comment exporter / importer un filtre d'import).
Les modes d'exécution
Un filtre d'import appliqué à un fichier peut être exploité en direct, à la demande, en mode batch (via la centrale d'import ou via un script déclenché en batch), lors de l'utilisation d'un connecteur sur une base externe.
Format des données
Texte tabulé (ou tab - tab / retour)
Cette structure est la plus simple et la plus répandue. Il est possible de réaliser un tel fichier avec n'importe quel éditeur de textes ou avec un tableur. Le principe est que chaque enregistrement est séparé du suivant par un retour à la ligne et chaque information est séparée de la suivante par une tabulation.
A l'aide du tableur intégré de Kentika, nous pouvons créer un fichier de films

Ce fichier est enregistré en texte tabulé

et peut être ouvert avec n'importe quel éditeur de texte ou traitement de texte.
Dans le cas où un champ peut avoir plusieurs valeurs (exemple : Charles Bronson et Henri Fonda), on s'assurera qu'il existe bien un séparateur entre ces valeurs et que l'on pourra utiliser ce séparateur afin d'isoler chacune de ces valeurs.
Texte avec étiquettes
Dans un fichier de ce type, en général, une ligne ne comporte qu'une information, les enregistrements sont séparés entre eux par une ligne vide. Les premiers caractères de chaque ligne permettent d'identifier la nature de l'information qui suit. Ce format est particuièrement adapté aux échanges de données documentaires car il assure une bonne lisibilité et permet des structures variables d'un enregistrement à l'autre (ie : toutes les étiquettes ne sont pas forcément présentes pour tous les enregistrements).
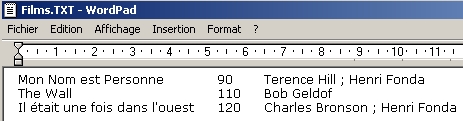
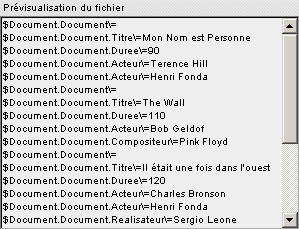
Exemple de texte avec étiquettes
Titre: Mon Nom est Personne
Durée: 90
Acteurs: Terence Hill ; Henri Fonda
Titre: The Wall
Durée: 110
Acteurs: Bob Geldof
Compositeur: Pink Floyd
Titre: Il était une fois dans l'ouest
Durée: 120
Acteurs: Charles Bronson ; Henri Fonda
Réalisateur: Sergio Leone
Texte indenté
Ce cas ne s'applique qu'au thesaurus et ne peut être traité qu'à l'aide de la fonction "importer un thesaurus".
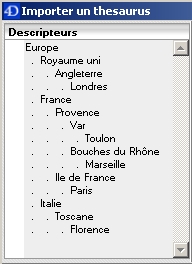
Un thesaurus saisi à l'aide d'un éditeur de texte

Peut être utilisé pour alimenter son thesaurus
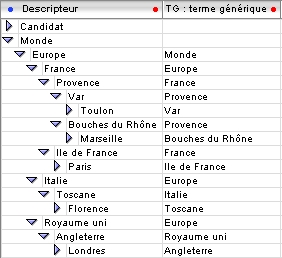
Après import, toute la structure est reproduite dans votre application
Thesaurus dans l'explorateur de données
L'import d'un thesaurus au format Kentika (et incluant l'ensemble des relations) utilise cette même option d'import. L'option d'export de thesaurus est en fait une des options proposées lorsque l'on active la fonction d'impression du thesaurus.
Fichier XML
Un tel fichier subit une première étape de conversion. Avant de procéder à l'élaboration du filtre d'import, il est possible d'en vérifier le contenu à l'aide de l'analyseur XML.
Le fichier dont la source xml est :
S'affiche comme ceci dans un navigateur

et subit une première conversion lors de l'ouverture par l'assistant d'import de données
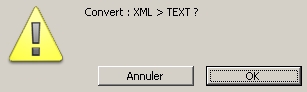
afin d'être ramené au cas d'un import de texte avec étiquette
Marc 2709
Ce format est spécifique au monde des bibliothèques. Il a été élaboré à une époque où les données étaient lues à partir de bandes et permettait une analyse d'un flux continu. En 2709, un enregistrement est composé de deux parties : un en-tête où sont indiqués les emplacements (offset) des données, leur nature (étiquette numérique sur 3 caractères) et leur longueur ; une partie données dont la longueur peut être variable mais où les début et fin des valeurs sont tranmsies dans l'en-tête.
Exemple de fichier 2709
01515cam 22003734a 4500001000900000005001700009008004100026
906004500067
925004200112
955008200154
010001700236
040002800253
020002200281
035002300303
042001500326
043001200341
050002400353
100002100377
245022800398
260006400626
300004000690
490002900730
440001500759
504005100774
651003900825
650003200864
650005200896
700002300948
700003600971
700002001007
700002201027
830008101049
985001101130
1439793020070208084441.0060602s2005 ua ae b m001 0 fre c a7bibccpccadapd3encipf20gy-gencatlg0 aacquireb1 shelf copyxpolicy default awe44 2006-06-02 z-processor to RCCDdys02 2007-02-08eys02 2007-02-08 to BCCD a 2005461872 aEQOcEQOdTZTdNDDdDLC a2724703782 (pbk.) a(OCoLC)ocm62462584 apccalcode af-ua---00aDT73.D33bC378 20051 aCastel, Georges.14aLes cimetiáeres est et ouest du mastaba de Khentika :bOasis de Dakhla /cGeorges Castel, Laure Pantalacci ; Tadeusz Dzierzykray-Rogalski, Moheb Shaaban (matâeriel anthropologique) ; Sylvie Marchand (câeramique d'une tombe) aCaire :bInstitut francais d'archâeologie orientale,c2005. avi, 584 p. ;bill., plans ;c32 cm.1 aFouilles de l'Ifao ;v52 0aBalat ;v7 aIncludes bibliographical references and index. 0aDakhla Oasis (Egypt)xAntiquities. 0aTombszEgyptzDakhla Oasis. 0aExcavations (Archaeology)zEgyptzDakhla Oasis.1 aPantalacci, Laure.1 aDzierçzykray-Rogalski, Tadeusz.1 aShaaban, Moheb.1 aMarchand, Sylvie. 0aFouilles de l'Institut fran?cais d'archâeologie orientale du Caire ;vt. 52. eODE-ca
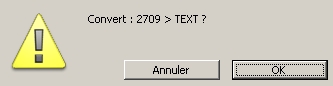
La demande de conversion n'est pas automatique, il faut maintenir la touche Majuscule enfoncée lors de la sélection du fichier à importer.
Et le même fichier converti
Record 01515cam 22003734a 45001439793020070208084441.0060602s2005 ua ae b m001 0 fre c
906$a 7
906$b ibc
906$c pccadap
906$d 3
906$e ncip
906$f 20
906$g y-gencatlg
925$a acquire
925$b 1 shelf copy
925$x policy default
955$a we44 2006-06-02 z-processor to RCCD
955$d ys02 2007-02-08
955$e ys02 2007-02-08 to BCCD
010$a 2005461872
040$a EQO
040$c EQO
040$d TZT
040$d NDD
040$d DLC
020$a 2724703782 (pbk.)
035$a (OCoLC)ocm62462584
042$a pcc
042$a lcode
043$a f-ua---
050$a DT73.D33
050$b C378 2005
100$a Castel, Georges.
245$a Les cimetières est et ouest du mastaba de Khentika :
245$b Oasis de Dakhla /
245$c Georges Castel, Laure Pantalacci ; Tadeusz Dzierzykray-Rogalski, Moheb Shaaban (matériel anthropologique) ; Sylvie Marchand (céramique d'une tombe)
260$a Caire :
260$b Institut francais d'archéologie orientale,
260$c 2005.
300$a vi, 584 p. ;
300$b ill., plans ;
300$c 32 cm.
490$a Fouilles de l'Ifao ;
490$v 52
440$a Balat ;
440$v 7
504$a Includes bibliographical references and index.
651$a Dakhla Oasis (Egypt)
651$x Antiquities.
650$a Tombs
650$z Egypt
650$z Dakhla Oasis.
650$a Excavations (Archaeology)
650$z Egypt
650$z Dakhla Oasis.
700$a Pantalacci, Laure.
700$a DzierÁzykray-Rogalski, Tadeusz.
700$a Shaaban, Moheb.
700$a Marchand, Sylvie.
830$a Fouilles de l'Institut fran?cais d'archéologie orientale du Caire ;
830$v t. 52.
985$e ODE-ca
Fichier html
Un tel fichier ne peut être traité qu'avec un connecteur (sauf cas exceptionnel). En effet, le html est conçu pour afficher des informations lisibles par un être humain et non par un ordinateur.
Format interne Kentika
Les données au format Kentika font l'objet d'un programme spécifique d'import. Pour exporter des données dans ce format, vous devez avoir créé un script : Export_Records . Ce format est également celui utilisé dans les programmes de synchronisation.
Autres formats
En règle général, les autres formats de données (exemples : .rtf ou .doc ou encore .xls) ne vont pas pouvoir être intégrés sans phase intermédiaire de conversion.
Exemple
Le fichier rtf qui s'affiche comme ceci :

est composé en fait du code suivant
{\rtf1\ansi\ansicpg1252\deff0{\fonttbl{\f0\fnil\fcharset0 Courier New;}}
{\*\generator Msftedit 5.41.15.1507;}\viewkind4\uc1\pard\lang1036\b\f0\fs20 Titre\b0 : Mon Nom est Personne\par
\b Dur\'e9e\b0 : 90\par
\b Acteurs\b0 : Terence Hill ; Henri Fonda\par
\par
\b Titre\b0 : The Wall\par
\b Dur\'e9e\b0 : 110\par
\b Acteurs\b0 : Bob Geldof\par
\b Compositeur\b0 : Pink Floyd\par
\par
\b Titre\b0 : Il \'e9tait une fois dans l'ouest\par
\b Dur\'e9e\b0 : 120\par
\b Acteurs\b0 : Charles Bronson ; Henri Fonda\par
\b R\'e9alisateur\b0 : Sergio Leone\par
\par
\par
}
Il sera nécessaire de l'enregistrer sous la forme d'un document texte pour pouvoir l'importer.
Exporter / importer un filtre ou stratégie d'import
Un filtre d'import correspond à des données qui ne sont pas issues de Kentika, une stratégie d'import correspond à des enregistrements au format interne Kentika.
Un filtre (ou stratégie) d'import est un enregistrement de la table des maquettes. Pour faire afficher ces éléments dans la liste, il suffit de cliquer sur le menu hiérarchique situé en haut à droite de la liste et de sélectionner l'option correspondante.
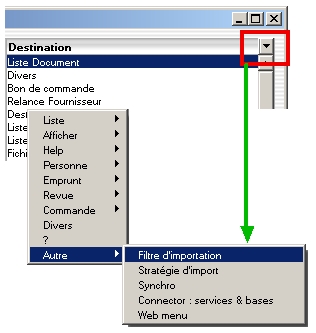
Ensuite, à l'aide du clic droit, demandez à ajouter l'enregistrement au panier.

Il est proposé de créer un fichier sur le disque lorsque vous refermez l'écran des préférences.
L'import de fait ensuite en utilisant la fonction d'import de données (objet, entre autres, du présent document).
Powered by KENTIKA Atomic - © Kentika 2025 tous droits réservés - Mentions légales