 +33 4 78 17 21 16
+33 4 78 17 21 16-


- Accueil
- |
-
 L'information à 360°
L'information à 360°
- |
- Solutions
- |
- Services
- |
- Clients
- |
- Société
- |
- Actualités
6 La navigation dans le manuel de Kentika est réservée aux utilisateurs identifiés
Importer des données textuelles
Appartenance & droits
Importer des données textuelles
Préambule
Cet import concerne la majorité des importations de données, à l'exception du format interne Kentika. Il présuppose que les données à importer sont déjà disponibles sous forme d'un fichier sur le disque de votre machine.
Un script doit être créé pour pouvoir activer cette fonction : IMP_Choix.
Le processus décrit ci-après concerne aussi bien la mise au point d'un filtre d'import que son exécution. Cependant, dans certains cas, vous pouvez mettre au point le filtre d'import sans l'exécuter (cas de l'import du résultat de l'exécution d'un connecteur ou du paramétrage de la centrale d'import) , ou bien exécuter un import à la demande en utilisant un filtre déjà réalisé.
L'import de données peut être un excercice très simple si les correspondances de champs sont faciles à établir mais peut s'avérer délicat si des traitements doivent être appliqués aux données avant leur intégration définitives dans la base de données.
Fonctionnement
La réalisation d'un import ou la mise au point d'un import s'effectue en 5 étapes :
- - Fichier : analyse du format des données et du codage des caractères
- - Structure des informations et destination des enregistrements (table et type d'objet)
- - Champs : identification, attributs, transformations
- - Traitement : simulation, exécution, enregistrement du filtre d'import
- - Résultat : après exécution, présente les enregistrements créés / modifiés dans chacune des tables
Format des données et codage des caractères
Après avoir sélectionné le fichier à importer, un premier traitement de conversion peut être effectué (cas du format XML ou du 2709).
Choix d'un fichier sur le disque
Le premier onglet permet de définir le format des données et le codage des caractères.
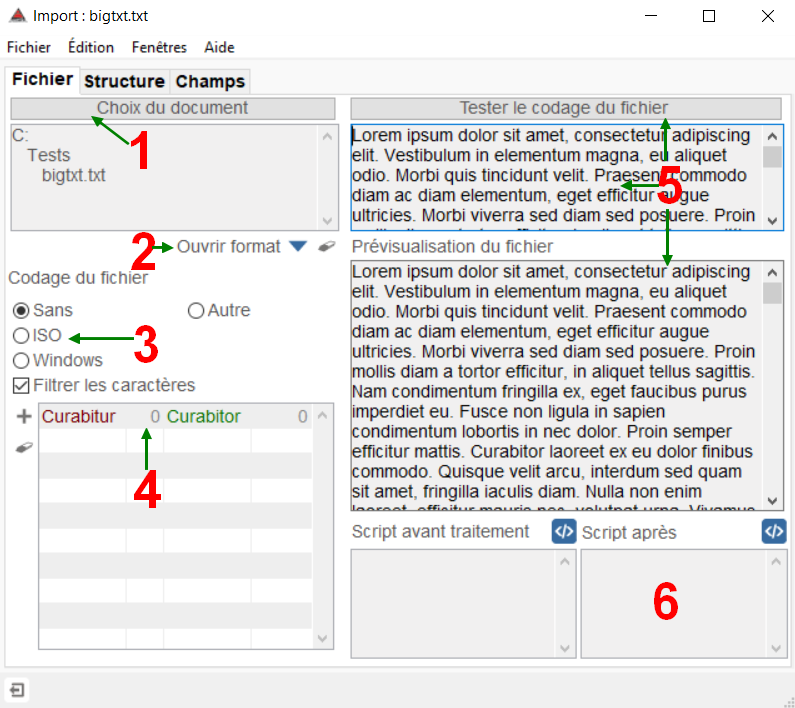 Import de données : document et codage
Import de données : document et codage
Document
1 Arborescence et possibilité de choisir un autre document
Choix d'un format (ou filtre)
2 Sélection d'un filtre pré-enregistré ou réinitialisation du filtre d'import
Par défaut, lors de l'ouverture de ce dialogue, le dernier filtre utilisé est chargé (qu'il ait été enregistré ou non comme format).
Codage des caractères
3 ISO ou windows, sans : pas de codage
Si dans la zone présentant le fichier brut (5 : haut) les caractères accentués n'apparaissent pas correctement, vous pouvez tester l'un des codages proposés. Après sélection d'un nouveau codage, il faut recliquer sur "Tester le codage du fichier".
Filtrer les caractères
4 Règles de transformation
Si aucun codage proposé ne convient ou si vous souhaitez opérer des transformations sur le contenu, vous pouvez créer un filtre appliqué aux caractères du contenu avant traitement.
Le principe est de remplacer un caractère ou une chaîne de caractères par un autre caractère ou une autre chaîne de caractères.
Filtrage de caractères unitaires
Un caractère unitaire sera toujours repéré par son code ascii et le remplacement sera effectué sur le caractère exact (un é sera dans ce cas différent de e ). Pour indiquer un caractère qui ne peut être saisi au clavier dans le dialogue demandant d'indiquer le caractère à remplacer (exemple : le caractère 254 de la table ascii qui ne peut être saisi au clavier), il suffit d'indiquer : ^suivi de son code ascii. Le caractère 13 (ou retour à la ligne) peut être indiqué sous la forme ^p ; le caractère 9 (ou tabulation) peut être indiquée sous la forme ^t.
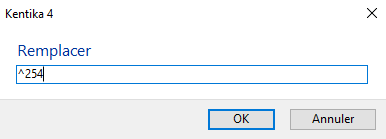
Pour remplacer un caractère par un autre, vous pouvez aussi le sélectionner préalablement dans la zone de texte initial (5 : haut), il sera alors proposé par défaut dans le dialogue ci-dessus.
Dans la liste des remplacements, les caractères unitaires sont indiqués avec à leur droite leur code ascii.
Filtrage d'une chaîne de caractères
Il est possible de remplacer complètement une chaîne de caractères par une autre. Ceci peut être utilisé dans le cas où les caractères accentués sont exprimés sur plusieurs caractères (exemple : é pour é en html) ou bien dans le cas de remplacement d'une valeur par une autre.
Exemple : si dans le fichier à importer le code langue correspondant à anglais est AN et que dans votre base de données le code est EN, il peut être intéressant d'appliquer une transformation avant d'affecter cette valeur à la rubrique langue.
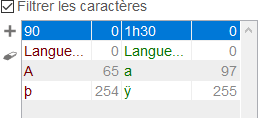
Dans l'exemple ci-dessus, la chaîne de caractère 90 sera remplacée par 1h30 ; les A majuscules (caractère 65) par des a minuscules (caractère 97) ; le caractère 254 par le caractère 255 et l'expression complète "Langue: AN" par l'expression "Langue:EN"
Précaution : l'application effectue des remplacements tant qu'il reste des remplacements à effectuer. Il faut donc veiller à ce que la chaîne que l'on demande à remplacer ne soit pas inclue dans la chaîne de remplacement.
Tester le codage du fichier
5 Si un filtrage de caractères a été saisi, permet de vérifier le résultat.
Avant de poursuivre, il est indispensable de s'assurer que les filtrages saisis fournissent un résultat correct. Vous ne devez passer à l'étape suivante qu'après vérification du résultat.
Script avant traitement et après traitement
6 Mode avancé, réservé à des spécialistes.
Dans certains cas, il peut s'avérer nécessaire d'effectuer des opérations avant que ne commence le traitement du fichier à importer ou bien lorsque le traitement est terminé. Un script peut alors être exécuté.
Exemples : dans le cas d'import de données en provenance d'un connecteur, il est parfois nécessaire d'aller chercher des informations complémentaires dans le fichier source d'orgine ; après un import en mode batch, un email à l'administrateur peut être généré afin de lui faire part du résultat de l'import ...
Cette première étape étant réalisée, cliquez sur l'onglet "Structure" pour poursuivre la mise au point du filtre d'import.
Powered by KENTIKA Atomic - © Kentika 2025 tous droits réservés - Mentions légales